Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
There's a lot of useful data inside a work. When you use the API to get a single work or lists of works, this is what's returned.
abstract_inverted_indexObject: The abstract of the work, as an inverted index, which encodes information about the abstract's words and their positions within the text. Like Microsoft Academic Graph, OpenAlex doesn't include plaintext abstracts due to legal constraints.
Newer works are more likely to have an abstract inverted index. For example, over 60% of works in 2022 have abstract data, compared to 45% for works older than 2000. Full chart is below:
alternate_host_venues (deprecated)The host_venue and alternate_host_venues properties have been deprecated in favor of primary_location and locations. The attributes host_venue and alternate_host_venues are no longer available in the Work object, and trying to access them in filters or group-bys will return an error.
authorshipsList: List of Authorship objects, each representing an author and their institution. Limited to the first 100 authors to maintain API performance.
For more information, see the Authorship object page.
apc_listObject: Information about this work's APC (article processing charge). The object contains:
value: Integer
currency: String
provenance: String — the source of this data. Currently the only value is “doaj” (DOAJ)
value_usd: Integer — the APC converted into USD
This value is the APC list price–the price as listed by the journal’s publisher. That’s not always the price actually paid, because publishers may offer various discounts to authors. Unfortunately we don’t always know this discounted price, but when we do you can find it in apc_paid.
Currently our only source for this data is DOAJ, and so doaj is the only value for apc_list.provenance, but we’ll add other sources over time.
We currently don’t have information on the list price for hybrid journals (toll-access journals that also provide an open-access option), but we will add this at some point. We do have apc_paid information for hybrid OA works occasionally.
You can use this attribute to find works published in Diamond open access journals by looking at works where apc_list.value is zero. See open_access.oa_status for more info.
apc_paidObject: Information about the paid APC (article processing charge) for this work. The object contains:
value: Integer
currency: String
provenance: String — currently either openapc or doaj, but more will be added; see below for details.
value_usd: Integer — the APC converted into USD
You can find the listed APC price (when we know it) for a given work using apc_list. However, authors don’t always pay the listed price; often they get a discounted price from publishers. So it’s useful to know the APC actually paid by authors, as distinct from the list price. This is our effort to provide this.
Our best source for the actually paid price is the OpenAPC project. Where available, we use that data, and so apc_paid.provenance is openapc. Where OpenAPC data is unavailable (and unfortunately this is common) we make our best guess by assuming the author paid the APC list price, and apc_paid.provenance will be set to wherever we got the list price from.
best_oa_locationObject: A Location object with the best available open access location for this work.
We score open locations to determine which is best using these factors:
Must have is_oa: true
type_:_ "publisher" is better than "repository".
version: "publishedVersion" is better than "acceptedVersion", which is better than "submittedVersion".
pdf_url: A location with a direct PDF link is better than one without.
repository rankings: Some major repositories like PubMed Central and arXiv are ranked above others.
biblioObject: Old-timey bibliographic info for this work. This is mostly useful only in citation/reference contexts. These are all strings because sometimes you'll get fun values like "Spring" and "Inside cover."
volume (String)
issue (String)
first_page (String)
last_page (String)
citation_normalized_percentileObject: The percentile of this work's citation count normalized by work type, publication year, and subfield. This field represents the same information as the FWCI expressed as a percentile. Learn more in the reference article: Field Weighted Citation Impact (FWCI).
cited_by_api_urlString: A URL that uses the cites filter to display a list of works that cite this work. This is a way to expand cited_by_count into an actual list of works.
cited_by_countInteger: The number of citations to this work. These are the times that other works have cited this work: Other works ➞ This work.
conceptsList: List of dehydrated Concept objects.
Each Concept object in the list also has one additional property:
score (Float): The strength of the connection between the work and this concept (higher is stronger). This number is produced by AWS Sagemaker, in the last layer of the machine learning model that assigns concepts.
Concepts with a score of at least 0.3 are assigned to the work. However, ancestors of an assigned concept are also added to the work, even if the ancestor scores are below 0.3.
Because ancestor concepts are assigned to works, you may see concepts in works with very low scores, even some zero scores.
corresponding_author_idsList: OpenAlex IDs of any authors for which authorships.is_corresponding is true.
corresponding_institution_idsList: OpenAlex IDs of any institutions found within an authorship for which authorships.is_corresponding is true.
countries_distinct_countInteger: Number of distinct country_codes among the authorships for this work.
counts_by_yearList: Works.cited_by_count for each of the last ten years, binned by year. To put it another way: each year, you can see how many times this work was cited.
Any citations older than ten years old aren't included. Years with zero citations have been removed so you will need to add those in if you need them.
created_dateString: The date this Work object was created in the OpenAlex dataset, expressed as an ISO 8601 date string.
display_nameString: Exactly the same as Work.title. It's useful for Works to include a display_name property, since all the other entities have one.
doiString: The DOI for the work. This is the Canonical External ID for works.
Occasionally, a work has more than one DOI--for example, there might be one DOI for a preprint version hosted on bioRxiv, and another DOI for the published version. However, this field always has just one DOI, the DOI for the published work.
fulltext_originString: If a work's full text is searchable in OpenAlex (has_fulltext is true), this tells you how we got the text. This will be one of:
pdf: We used Grobid to get the text from an open-access PDF.
ngrams: Full text search is enabled using N-grams obtained from the Internet Archive.
This attribute is only available for works with has_fulltext:true.
fwciFloat: The Field-weighted Citation Impact (FWCI), calculated for a work as the ratio of citations received / citations expected in the year of publications and three following years. Learn more in the reference article: Field Weighted Citation Impact (FWCI).
grantsList: List of grant objects, which include the Funder and the award ID, if available. Our grants data comes from Crossref, and is currently fairly limited.
has_fulltextBoolean: Set to true if the work's full text is searchable in OpenAlex. This does not necessarily mean that the full text is available to you, dear reader; rather, it means that we have indexed the full text and can use it to help power searches. If you are trying to find the full text for yourself, try looking in open_access.oa_url.
We get access to the full text in one of two ways: either using an open-access PDF, or using N-grams obtained from the Internet Archive. You can learn where a work's full text came from at fulltext_origin.
host_venue (deprecated)The host_venue and alternate_host_venues properties have been deprecated in favor of primary_location and locations. The attributes host_venue and alternate_host_venues are no longer available in the Work object, and trying to access them in filters or group-bys will return an error.
idString: The OpenAlex ID for this work.
idsObject: All the external identifiers that we know about for this work. IDs are expressed as URIs whenever possible. Possible ID types:
mag (Integer: the Microsoft Academic Graph ID)
openalex (String: The OpenAlex ID. Same as Work.id)
pmid (String: The Pubmed Identifier)
pmcid (String: the Pubmed Central identifier)
Most works are missing one or more ID types (either because we don't know the ID, or because it was never assigned). Keys for null IDs are not displayed.
indexed_inList: The sources this work is indexed in. Possible values: arxiv, crossref, doaj, pubmed.
institutions_distinct_countInteger: Number of distinct institutions among the authorships for this work.
is_paratextBoolean: True if we think this work is paratext.
In our context, paratext is stuff that's in a scholarly venue (like a journal) but is about the venue rather than a scholarly work properly speaking. Some examples and nonexamples:
yep it's paratext: front cover, back cover, table of contents, editorial board listing, issue information, masthead.
no, not paratext: research paper, dataset, letters to the editor, figures
Turns out there is a lot of paratext in registries like Crossref. That's not a bad thing... but we've found that it's good to have a way to filter it out.
We determine is_paratext algorithmically using title heuristics.
is_retractedBoolean: True if we know this work has been retracted.
We identify works that have been retracted using the public Retraction Watch database, a public resource made possible by a partnership between Crossref and The Center for Scientific Integrity.
keywordsList of objects: Short phrases identified based on works' Topics. For background on how Keywords are identified, see the Keywords page at OpenAlex help pages.
The score for each keyword represents the similarity score of that keyword to the title and abstract text of the work.
We provide up to 5 keywords per work, for all keywords with scores above a certain threshold.
languageString: The language of the work in ISO 639-1 format. The language is automatically detected using the information we have about the work. We use the langdetect software library on the words in the work's abstract, or the title if we do not have the abstract. The source code for this procedure is here. Keep in mind that this method is not perfect, and that in some cases the language of the title or abstract could be different from the body of the work.
A few things to keep in mind about this:
We don't always assign a language if we do not have enough words available to accurately guess.
We report the language of the metadata, not the full text. For example, if a work is in French, but the title and abstract are in English, we report the language as English.
In some cases, abstracts are in two different languages. Unfortunately, when this happens, what we report will not be accurate.
licenseString: The license applied to this work at this host. Most toll-access works don't have an explicit license (they're under "all rights reserved" copyright), so this field generally has content only if is_oa is true.
locationsList: A list of Location objects describing all unique places where this work lives.
locations_countInteger: Number of locations for this work.
meshList: List of MeSH tag objects. Only works found in PubMed have MeSH tags; for all other works, this is an empty list.
open_accessObject: Information about the access status of this work, as an OpenAccess object.
primary_locationObject: A Location object with the primary location of this work.
The primary_location is where you can find the best (closest to the version of record) copy of this work. For a peer-reviewed journal article, this would be a full text published version, hosted by the publisher at the article's DOI URL.
primary_topicObject
The top ranked Topic for this work. This is the same as the first item in Work.topics.
publication_dateString: The day when this work was published, formatted as an ISO 8601 date.
Where different publication dates exist, we usually select the earliest available date of electronic publication.
This date applies to the version found at Work.url. The other versions, found in Work.locations, may have been published at different (earlier) dates.
publication_yearInteger: The year this work was published.
This year applies to the version found at Work.url. The other versions, found in Work.locations, may have been published in different (earlier) years.
referenced_worksList: OpenAlex IDs for works that this work cites. These are citations that go from this work out to another work: This work ➞ Other works.
related_worksList: OpenAlex IDs for works related to this work. Related works are computed algorithmically; the algorithm finds recent papers with the most concepts in common with the current paper.
sustainable_development_goalsList: List of objects
The United Nations' 17 Sustainable Development Goals are a collection of goals at the heart of a global "shared blueprint for peace and prosperity for people and the planet." We use a machine learning model to tag works with their relevance to these goals based on our OpenAlex SDG Classifier, an mBERT machine learning model developed by the Aurora Universities Network. The score represents the model's predicted probability of the work's relevance for a particular goal.
We display all of the SDGs with a prediction score higher than 0.4.
topicsList: List of objects
The top ranked Topics for this work. We provide up to 3 topics per work.
titleString: The title of this work.
This is exactly the same as Work.display_name. We include both attributes with the same information because we want all entities to have a display_name, but there's a longstanding tradition of calling this the "title," so we figured you'll be expecting works to have it as a property.
typeString: The type of the work.
You can see all of the different types along with their counts in the OpenAlex API here: https://api.openalex.org/works?group_by=type.
Most works are type article. This includes what was formerly (and currently in type_crossref) labeled as journal-article, proceedings-article, and posted-content. We consider all of these to be article type works, and the distinctions between them to be more about where they are published or hosted:
Journal articles will have a primary_location.source.type of journal
Conference proceedings will have a primary_location.source.type of conference
Preprints or "posted content" will have a primary_location.version of submittedVersion
(Note that distinguishing between journals and conferences is a hard problem, one we often get wrong. We are working on improving this, but we also point out that the two have a lot of overlap in terms of their roles as hosts of research publications.)
Works that are hosted primarily on a preprint, or that are identified speicifically as preprints in the metadata we receive, are assigned the type preprint rather than article.
Works that represent stuff that is about the venue (such as a journal)—rather than a scholarly work properly speaking—have type paratext. These include things like front-covers, back-covers, tables of contents, and the journal itself (e.g., https://openalex.org/W4232230324).
We also have types for letter , editorial , erratum (corrections), libguides , supplementary-materials , and review (currently, articles that come from journals that exclusively publish review articles). Coverage is low on these but will improve.
Other work types follow the Crossref "type" controlled vocabulary—see type_crossref.
type_crossrefString: Legacy type information, using Crossref's "type" controlled vocabulary.
These are the work types that we used to use, before switching to our current system (see type).
You can see all possible values of Crossref's "type" controlled vocabulary via the Crossref api here: https://api.crossref.org/types.
Where possible, we just pass along Crossref's type value for each work. When that's impossible (eg the work isn't in Crossref), we do our best to figure out the type ourselves.
updated_dateString: The last time anything in this Work object changed, expressed as an ISO 8601 date string (in UTC). This date is updated for any change at all, including increases in various counts.
OpenAccess objectThe OpenAccess object describes access options for a given work. It's only found as part of the Work object.
any_repository_has_fulltextBoolean: True if any of this work's locations has location.is_oa=true and location.source.type=repository.
Use case: researchers want to track Green OA, using a definition of "any repository hosts this." OpenAlex's definition (as used in oa_status) doesn't support this, because as soon as there's a publisher-hosted copy (bronze, hybrid, or gold), oa_status is set to that publisher-hosted status.
So there's a lot of repository-hosted content that the oa_status can't tell you about. Our State of OA paper calls this "shadowed Green." This feature makes it possible to track shadowed Green.
is_oaBoolean: True if this work is Open Access (OA).
There are many ways to define OA. OpenAlex uses a broad definition: having a URL where you can read the fulltext of this work without needing to pay money or log in. You can use the locations and oa_status fields to narrow your results further, accommodating any definition of OA you like.
oa_statusString: The Open Access (OA) status of this work. Possible values are:
gold: Published in a fully OA journal.
green: Toll-access on the publisher landing page, but there is a free copy in an OA repository.
hybrid: Free under an open license in a toll-access journal.
bronze: Free to read on the publisher landing page, but without any identifiable license.
closed: All other articles.
oa_urlString: The best Open Access (OA) URL for this work.
Although there are many ways to define OA, in this context an OA URL is one where you can read the fulltext of this work without needing to pay money or log in. The "best" such URL is the one closest to the version of record.
This URL might be a direct link to a PDF, or it might be to a landing page that links to the free PDF
Query the OpenAlex dataset using the magic of The Internet
If you open these examples in a web browser, they will look much better if you have a browser plug-in such as JSONVue installed.
You can use the institutions endpoint to learn about universities and research centers. OpenAlex has a powerful search feature that searches across 108,000 institutions.
Lets use it to search for Stanford University:
Find Stanford University
https://api.openalex.org/institutions?search=stanford
Our first result looks correct (yeah!):
We can use the ID https://openalex.org/I97018004 in that result to find out more.
Show works where at least one author is associated with Stanford University
https://api.openalex.org/works?filter=institutions.id:https://openalex.org/I97018004
This is just one of the 50+ ways that you can filter works!
Right now the list shows records for all years. Lets narrow it down to works that were published between 2010 to 2020, and sort from newest to oldest.
Show works with publication years 2010 to 2020, associated with Stanford University https://api.openalex.org/works?filter=institutions.id:https://openalex.org/I97018004,publication_year:2010-2020&sort=publication_date:desc
Finally, you can group our result by publication year to get our final result, which is the number of articles produced by Stanford, by year from 2010 to 2020. There are more than 30 ways to group records in OpenAlex, including by publisher, journal, and open access status.
That gives a result like this:
Jump into an area of OpenAlex that interests you:
And check out our tutorials page for some hands-on examples!
OpenAlex is:
Big — We have about twice the coverage of the other services, and have significantly better coverage of non-English works and works from the Global South.
Easy — Our service is fast, modern, and well-documented.
Open — Our complete dataset is free under the CC0 license, which allows for transparency and reuse.
Priem, J., Piwowar, H., & Orr, R. (2022). OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts. ArXiv. https://arxiv.org/abs/2205.01833
Learn more about the OpenAlex entities:
The Location object describes the location of a given work. It's only found as part of the Work object.
There are three places in the Work object where you can find locations:
is_acceptedis_oaBoolean: True if an Open Access (OA) version of this work is available at this location.
is_publishedString: The landing page URL for this location.
The concept of a source is meant to capture a certain social relationship between the host organization and a version of a work. When an organization puts the work on the internet, there is an understanding that they have, at some level, endorsed the work. This level varies, and can be very different depending on the source!
String: A URL where you can find this location as a PDF.
publishedVersion: The document’s version of record. This is the most authoritative version.
acceptedVersion: The document after having completed peer review and being officially accepted for publication. It will lack publisher formatting, but the content should be interchangeable with the that of the publishedVersion.
submittedVersion: the document as submitted to the publisher by the authors, but before peer-review. Its content may differ significantly from that of the accepted article.
It's easy to get a work from from the API with: /works/<entity_id> Here's an example:
You can look up works using external IDs such as a DOI:
You can use the full ID or a shorter Uniform Resource Name (URN) format like so:
Available external IDs for works are:
You must make sure that the ID(s) you supply are valid and correct. If an ID you request is incorrect, you will get no result. If you request an illegal ID—such as one containing a , or &, the query will fail and you will get a 403 error.
affiliationsList: List of objects
authorauthor_positionString: A summarized description of this author's position in the work's author list. Possible values are first, middle, and last.
It's not strictly necessary, because author order is already implicitly recorded by the list order of Authorship objects; however it's useful in some contexts to have this as a categorical value.
countriesList: The country or countries for this author.
We determine the countries using a combination of matched institutions and parsing of the raw affiliation strings, so we can have this information for some authors even if we do not have a specific institutional affiliation.
institutionsis_correspondingBoolean: If true, this is a corresponding author for this work.
This is a new feature, and the information may be missing for many works. We are working on this, and coverage will improve soon.
raw_affiliation_stringsList: This author's affiliation as it originally came to us (on a webpage or in an API), as a list of raw unformatted strings. If there is only one affiliation, it will be a list of length one.
raw_author_nameString: This author's name as it originally came to us (on a webpage or in an API), as a raw unformatted string.
Lets use the OpenAlex API to get journal articles and books published by authors at Stanford University. We'll limit our search to articles published between 2010 and 2020. Since OpenAlex is free and openly available, these examples work without any login or account creation.
The works endpoint contains over 240 million articles, books, and theses . We can filter to show works associated with Stanford.
There you have it! This same technique can be applied to hundreds of questions around scholarly data. The data you received is under a CC0 license, so not only did you access it easily, you can share it freely!
is a fully open catalog of the global research system. It's named after the and made by the nonprofit .
This is the technical documentation for OpenAlex, including the and the . Here, you can learn how to set up your code to access OpenAlex's data. If you want to explore the data as a human, you may be more interested in .
The OpenAlex dataset describes scholarly and how those entities are connected to each other. Types of entities include , , , , , , and .
Together, these make a huge web (or more technically, heterogeneous directed ) of hundreds of millions of entities and billions of connections between them all.
Learn more at our general help center article:
We offer a fast, modern REST API to get OpenAlex data programmatically. It's free and requires no authentication. The daily limit for API calls is 100,000 requests per user per day. For best performance, to all API requests, like mailto=example@domain.com.
There is also a complete database snapshot available to download.
The API has a limit of 100,000 calls per day, and the snapshot is updated monthly. If you need a higher limit, or more frequent updates, please look into
The web interface for OpenAlex, built directly on top of the API, is the quickest and easiest way to .
OpenAlex offers an open replacement for industry-standard scientific knowledge bases like Elsevier's Scopus and Clarivate's Web of Science. these paywalled services, OpenAlex offers significant advantages in terms of inclusivity, affordability, and avaliability.
Many people and organizations have already found great value using OpenAlex. Have a look at the to hear what they've said!
For tech support and bug reports, please visit our . You can also join the , and follow us on and .
If you use OpenAlex in research, please cite :
The OpenAlex dataset describes scholarly entities and how those entities are connected to each other. Together, these make a huge web (or more technically, heterogeneous directed ) of hundreds of millions of entities and billions of connections between them all.
: Scholarly documents like journal articles, books, datasets, and theses
: People who create works
: Where works are hosted (such as journals, conferences, and repositories)
: Universities and other organizations to which authors claim affiliations
: Topics assigned to works
: Companies and organizations that distribute works
: Organizations that fund research
: Where things are in the world
Locations are meant to capture the way that a work exists in different versions. So, for example, a work may have a version that has been peer-reviewed and published in a journal (the ). This would be one of the work's locations. It may have another version available on a preprint server like —this version having been posted before it was accepted for publication. This would be another one of the work's locations.
Below is an example of a work in OpenAlex () that has multiple locations with different properties. The version of record, published in a peer-reviewed journal, is listed first, and is not open-access. The second location is a university repository, where one can find an open-access copy of the published version of the work. Other locations are listed below.
Locations are meant to cover anywhere that a given work can be found. This can include journals, proceedings, institutional repositories, and subject-area repositories like and . If you are only interested in a certain one of these (like journal), you can use a to specify the locations.source.type. ()
: The best (closest to the ) copy of this work.
: The best available open access location of this work.
: A list of all of the locations where this work lives. This will include the two locations above if availabe, and can also include other locations.
Boolean: true if this location's is either acceptedVersion or publishedVersion; otherwise false.
There are . OpenAlex uses a broad definition: having a URL where you can read the fulltext of this work without needing to pay money or log in.
Boolean: true if this location's is publishedVersion; otherwise false.
String: The location's publishing license. This can be a license such as cc0 or cc-by, a publisher-specific license, or null which means we are not able to determine a license for this location.
Object: Information about the source of this location, as a object.
String: The version of the work, based on the Possible values are:.
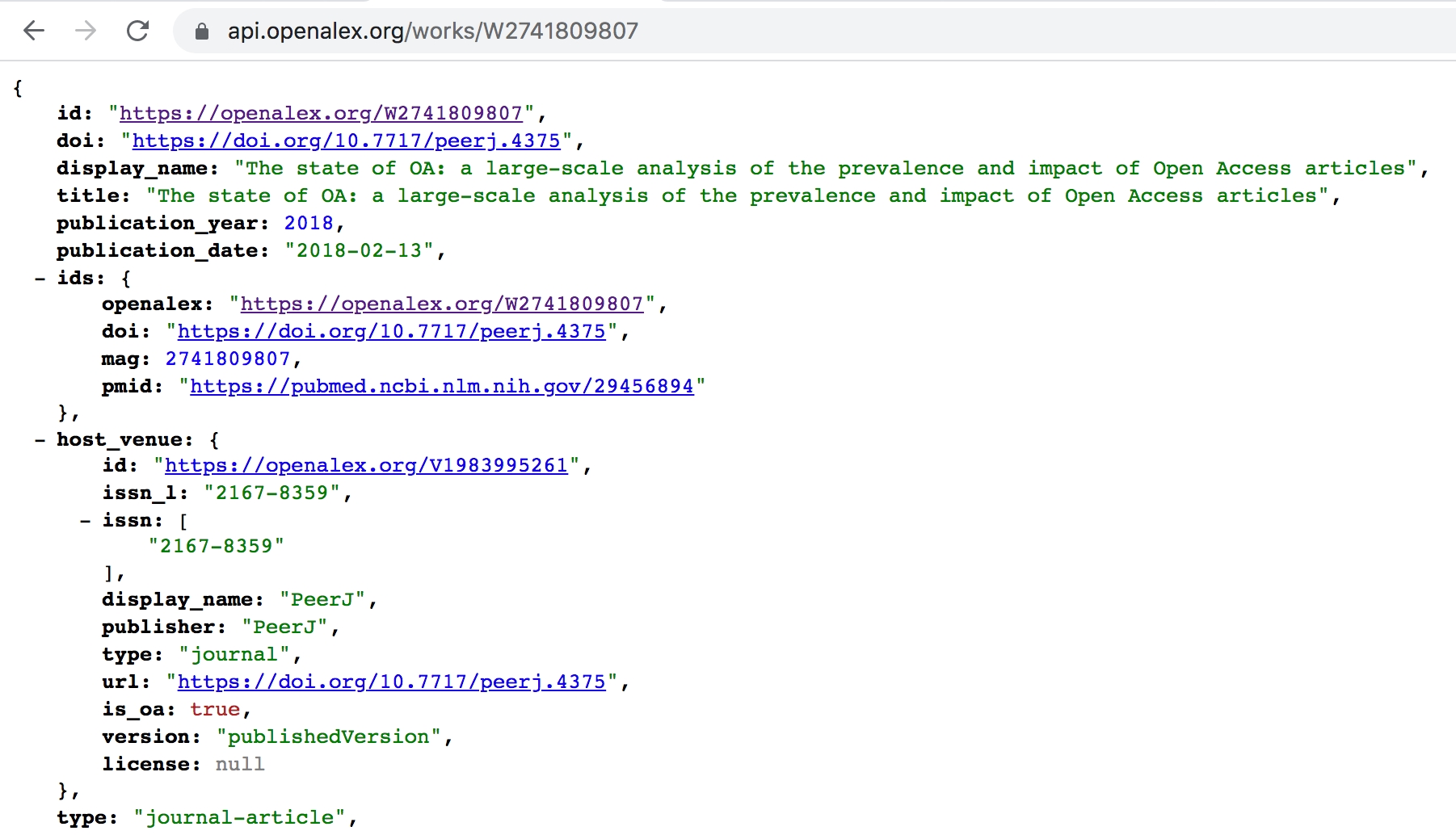
Get the work with the W2741809807:
That will return a object, describing everything OpenAlex knows about the work with that ID.
You can make up to 50 of these queries at once by requesting a list of entities and filtering on IDs ().
Get the work with this DOI: https://doi.org/10.7717/peerj.4375:
Get the work with PubMed ID: https://pubmed.ncbi.nlm.nih.gov/14907713:
You can use select to limit the fields that are returned in a work object. More details are .
Display only the id and display_name for a work object
The Authorship object represents a single author and her institutional affiliations in the context of a given work. It is only found as part of a Work object, in the property.
Each institutional affiliation that this author has claimed will be listed here: the raw affiliation string that we found, along with the OpenAlex ID or IDs that we matched it to.
This information will be redundant with below, but is useful if you need to know about what we used to match institutions.
String: An author of this work, as a dehydrated object.
Note that, sometimes, we assign ORCID using , so the ORCID we associate with an author was not necessarily included with this work.
List: The institutional affiliations this author claimed in the context of this work, as objects.
Get all of the works in OpenAlex
You can works and change the default number of results returned with the page and per-page parameters:
Get a second page of results with 50 results per page
You can with the sort parameter:
Sort works by publication year
Continue on to learn how you can and lists of works.
You can use sample to get a random batch of works. Read more about sampling and how to add a seed value .
Get 20 random works
You can use select to limit the fields that are returned in a list of works. More details are .
Display only the id and display_name within works results
DOI
doi
Microsoft Academic Graph (MAG)
mag
PubMed ID (PMID)
pmid
PubMed Central ID (PMCID)
pmcid
Journal articles, books, datasets, and theses
Works are scholarly documents like journal articles, books, datasets, and theses. OpenAlex indexes over 240M works, with about 50,000 added daily. You can access a work in the OpenAlex API like this:
Get a list of OpenAlex works:
https://api.openalex.org/works
That will return a list of Work object, describing everything OpenAlex knows about each work. We collect new works from many sources, including Crossref, PubMed, institutional and discipline-specific repositories (eg, arXiv). Many older works come from the now-defunct Microsoft Academic Graph (MAG).
Works are linked to other works via the referenced_works (outgoing citations), cited_by_api_url (incoming citations), and related_works properties.
Learn more about what you can do with works:
People who create works
Authors are people who create works. You can get an author from the API like this:
Get a list of OpenAlex authors:
https://api.openalex.org/authors
The Canonical External ID for authors is ORCID; only a small percentage of authors have one, but the percentage is higher for more recent works.
Our information about authors comes from MAG, Crossref, PubMed, ORCID, and publisher websites, among other sources. To learn more about how we combine this information to get OpenAlex Authors, see Author Disambiguation.
Authors are linked to works via the works.authorships property.
Learn more about what you can with authors:
N-grams are groups of sequential words that occur in the text of a Work.
Note that while n-grams are derived from the fulltext of a Work, the presence of n-grams for a given Work doesn't imply that the fulltext is available to you, the reader. It only means the fulltext was available to Internet Archive for indexing. Work.open_access is the place to go for information on public fulltext availability.
The n-gram API endpoint is not currently in service. The n-grams are still used on our backend to help power fulltext search. If you have any questions about this, please submit a support ticket.
You can see which works we have full-text for using the has_fulltext filter. This does not necessarily mean that the full text is available to you, dear reader; rather, it means that we have indexed the full text and can use it to help power searches. If you are trying to find the full text for yourself, try looking in open_access.oa_url.
We get access to the full text in one of two ways: either using an open-access PDF, or using N-grams obtained from the Internet Archive. You can learn where a work's full text came from at fulltext_origin.
About 57 million works have n-grams coverage through Internet Archive. OurResearch is the first organization to host this data in a highly usable way, and we are proud to integrate it into OpenAlex!
Curious about n-grams used in search? Browse them all via the API. Highly-cited works and less recent works are more likely to have n-grams, as shown by the coverage charts below:
It's easy to filter works with the filter parameter:
In this example the filter is publication_year and the value is 2020.
/works attribute filters/works convenience filtersabstract.searchText search using abstracts
Value: a search string
authors_countNumber of authors for a work
Value: an Integer
authorships.institutions.continent (alias: institutions.continent)Returns: works where at least one of the author's institutions is in the chosen continent.
authorships.institutions.is_global_south (alias: institutions.is_global_south)Value: a Boolean (true or false)
best_open_versionValue: a String with one of the following values:
any: This means that best_oa_location.version = submittedVersion, acceptedVersion, or publishedVersion
acceptedOrPublished: This means that best_oa_location.version can be acceptedVersion or publishedVersion
published: This means that best_oa_location.version = publishedVersion
cited_bycitesconcepts_countValue: an Integer
default.searchText search across titles, abstracts, and full text of works
Value: a search string
display_name.search (alias: title.search)Text search across titles for works
Value: a search string
from_created_dateValue: a date, formatted as yyyy-mm-dd
from_publication_dateValue: a date, formatted as yyyy-mm-dd
Filtering by publication date is not a reliable way to retrieve recently updated and created works, due to the way publishers assign publication dates. Use from_created_date or from_updated_date to get the latest changes in OpenAlex.
from_updated_datefulltext.searchValue: a search string
We combined some n-grams before storing them in our search database, so querying for an exact phrase using quotes does not always work well.
has_abstractWorks that have an abstract available
Value: a Boolean (true or false)
Returns: works that have or lack an abstract, depending on the given value.
has_doiValue: a Boolean (true or false)
has_oa_accepted_or_published_versionValue: a Boolean (true or false)
has_oa_submitted_versionValue: a Boolean (true or false)
has_orcidValue: a Boolean (true or false)
has_pmcidValue: a Boolean (true or false)
has_pmidValue: a Boolean (true or false)
has_ngrams (DEPRECATED)Works that have n-grams available to enable full-text search in OpenAlex.
Value: a Boolean (true or false)
has_referencesValue: a Boolean (true or false)
journallocations.source.host_institution_lineagelocations.source.publisher_lineagemag_onlyValue: a Boolean (true or false)
Returns: works which came from MAG (Microsoft Academic Graph), and no other data sources.
primary_location.source.has_issnValue: a Boolean (true or false)
primary_location.source.publisher_lineageraw_affiliation_strings.searchThis filter used to be named raw_affiliation_string.search, but it is now raw_affiliation_strings.search (i.e., plural, with an 's').
Value: a search string
related_torepositoryYou can also use this as a group_by to learn things about repositories:
title_and_abstract.searchText search across titles and abstracts for works
Value: a search string
to_created_dateValue: a date, formatted as yyyy-mm-dd
to_publication_dateValue: a date, formatted as yyyy-mm-dd
to_updated_dateversionValue: a String with value publishedVersion, submittedVersion, acceptedVersion, or null
Searching without a middle initial returns names with and without middle initials. So a search for "John Smith" will also return "John W. Smith".
When searching for authors, there is no difference when using the search parameter or the filter display_name.search, since display_name is the only field searched when finding authors.
You can autocomplete authors to create a very fast type-ahead style search function:
This returns a list of authors with their last known affiliated institution as the hint:
The following fields can be searched within works:
Rather than searching for the names of entities related to works—such as authors, institutions, and sources—you need to search by a more unique identifier for that entity, like the OpenAlex ID. This means that there is a 2 step process:
Why can't you do this in just one step? Well, if you use the search term, "NYU," you might end up missing the ones that use the full name "New York University," rather than the initials. Sure, you could try to think of all possible variants and search for all of them, but you might miss some, and you risk putting in search terms that let in works that you're not interested in. Figuring out which works are actually associated with the "NYU" you're interested shouldn't be your responsibility—that's our job! We've done that work for you, so all the relevant works should be associated with one unique ID.
You can autocomplete works to create a very fast type-ahead style search function:
This returns a list of works titles with the author of each work set as the hint:
affiliationsList: List of objects, representing the affiliations this author has claimed in their publications. Each object in the list has two properties:
years: a list of the years in which this author claimed an affiliation with this institution
cited_by_countcounts_by_yearAny works or citations older than ten years old aren't included. Years with zero works and zero citations have been removed so you will need to add those in if you need them.
created_datedisplay_nameString: The name of the author as a single string.
display_name_alternativesList: Other ways that we've found this author's name displayed.
idString: The OpenAlex ID for this author.
idsObject: All the external identifiers that we know about for this author. IDs are expressed as URIs whenever possible. Possible ID types:
twitter (String: this author's Twitter handle)
wikipedia (String: this author's Wikipedia page)
Most authors are missing one or more ID types (either because we don't know the ID, or because it was never assigned). Keys for null IDs are not displayed.
last_known_institution (deprecated)last_known_institutionsorcidCompared to other Canonical IDs, ORCID coverage is relatively low in OpenAlex, because ORCID adoption in the wild has been slow compared with DOI, for example. This is particularly an issue when dealing with older works and authors.
summary_statsObject: Citation metrics for this author
While the 2-year mean citedness is normally a journal-level metric, it can be calculated for any set of papers, so we include it for authors.
updated_dateworks_api_urlString: A URL that will get you a list of all this author's works.
We express this as an API URL (instead of just listing the works themselves) because sometimes an author's publication list is too long to reasonably fit into a single author object.
works_countx_conceptsscore (Float): The strength of association between this author and the listed concept, from 0-100.
Author objectTo see the full list of authors, go to the individual record for the work, which is never truncated.
This affects filtering as well. So if you filter works using an author ID or ROR, you will not receive works where that author is listed further than 100 places down on the list of authors. We plan to change this in the future, so that filtering works as expected.
You can filter authors with the filter parameter:
/authors attribute filtersWant to filter by last_known_institution.display_name? This is a two-step process:
Find the institution.id by searching institutions by display_name.
Filter works by last_known_institution.id.
/authors convenience filtersdefault.searchValue: a search string
display_name.searchValue: a search string
has_orcidValue: a Boolean (true or false)
last_known_institution.continentReturns: authors where where the last known institution is in the chosen continent.
last_known_institution.is_global_southValue: a Boolean (true or false)
You can filter sources with the filter parameter:
/sources attribute filtersWant to filter by host_organization.display_name? This is a two-step process:
Find the host organization's ID by searching by display_name in Publishers or Institutions, depending on which type you are looking for.
Filter works by host_organization.id.
/sources convenience filterscontinentReturns: sources that are associated with the chosen continent.
default.searchValue: a search string
display_name.searchValue: a search string
has_issnValue: a Boolean (true or false)
is_global_southValue: a Boolean (true or false)
Journals and repositories that host works
Sources are where works are hosted. OpenAlex indexes about 249,000 sources. There are several types, including journals, conferences, preprint repositories, and institutional repositories.
Our information about sources comes from Crossref, the ISSN Network, and MAG. These datasets are joined automatically where possible, but there’s also a lot of manual combining involved. We do not curate journals, so any journal that is available in the data sources should make its way into OpenAlex.
Learn more about what you can do with sources:
N-grams list the words and phrases that occur in the full text of a Work. We obtain them from Internet Archive's publicly (and generously ) available General Index and use them to enable fulltext searches on the Works that have them, through both the fulltext.search filter, and as an element of the more holistic search parameter.
Get works where the publication year is 2020
It's best to before trying these out. It will show you how to combine filters and build an AND, OR, or negation query.
You can filter using these attributes of the object (click each one to view their documentation on the Work object page):
The host_venue and alternate_host_venues properties have been deprecated in favor of and . The attributes host_venue and alternate_host_venues are no longer available in the Work object, and trying to access them in filters or group-bys will return an error.
(alias: author.id) — Authors for a work (OpenAlex ID)
(alias: author.orcid) — Authors for a work (ORCID)
(alias: institutions.country_code)
(alias: institutions.id) — Institutions affiliated with the authors of a work (OpenAlex ID)
(alias: institutions.ror) — Institutions affiliated with the authors of a work (ROR ID)
(alias: is_corresponding) — This filter marks whether or not we have corresponding author information for a given work
— The Open Acess license for a work
(alias: concept.id) — The concepts associated with a work
— Corresponding authors for a work (OpenAlex ID)
— The DOI (Digital Object Identifier) of a work
— Award IDs for grants
— Funding organizations linked to grants for a work
(alias: pmid)
(alias: openalex) — The OpenAlex ID for a work
(alias: mag)
(alias: is_oa) — Whether a work is Open Access
(alias: oa_status) — The Open Access status for a work (e.g., gold, green, hybrid, etc.)
Want to filter by the display_name of an associated entity (author, institution, source, etc.)?
These filters aren't attributes of the object, but they're handy for solving some common use cases:
Returns: works whose abstract includes the given string. See the for details on the search algorithm used.
Get works with abstracts that mention "artificial intelligence":
Returns: works with the chosen number of objects (authors). You can use the inequality filter to select a range, such as authors_count:>5.
Get works that have exactly one author
Value: a String with a valid
Get works where at least one author's institution in each work is located in Europe
Returns: works where at least one of the author's institutions is in the Global South ().
Get works where at least one author's institution is in the Global South
Returns: works that meet the above criteria for .
Get works whose best_oa_location is a submitted, accepted, or published version: ``
Value: the for a given work
Returns: works found in the given work's section. You can think of this as outgoing citations.
Get works cited by :
Value: the for a given work
Returns: works that cite the given work. This is works that have the given OpenAlex ID in the section. You can think of this as incoming citations.
Get works that cite : ``
The number of results returned by this filter may be slightly higher than the work'sdue to a timing lag in updating that field.
Returns: works with the chosen number of .
Get works with at least three concepts assigned
This works the same as using the for Works.
Returns: works whose (title) includes the given string; see the for details.
Get works with titles that mention the word "wombat":
For most cases, you should use the parameter instead of this filter, because it uses a better search algorithm and searches over abstracts as well as titles.
Returns: works with greater than or equal to the given date.
This field requires an
Get works created on or after January 12th, 2023 (does not work without valid API key):
Returns: works with greater than or equal to the given date.
Get works published on or after March 14th, 2001:
Value: a date, formatted as an date or date-time string (for example: "2020-05-17", "2020-05-17T15:30", or "2020-01-02T00:22:35.180390").
Returns: works with greater than or equal to the given date.
This field requires an
Get works updated on or after January 12th, 2023 (does not work without valid API key):
Learn more about using this filter to get the freshest data possible with our .
Returns: works whose fulltext includes the given string. Fulltext search is available for a subset of works, obtained either from PDFs or , see for more details.
Get works with fulltext that mention "climate change":
Get the works that have abstracts:
Returns: works that have or lack a DOI, depending on the given value. It's especially useful for .
Get the works that have no DOI assigned: ``
Returns: works with at least one of the has = true and is acceptedVersion or publishedVersion. For Works that undergo peer review, like journal articles, this means there is a peer-reviewed OA copy somewhere. For some items, like books, a published version doesn't imply peer review, so they aren't quite synonymous.
Get works with an OA accepted or published copy
Returns: works with at least one of the has = true and is submittedVersion. This is useful for finding works with preprints deposited somewhere.
Get works with an OA submitted copy: ``
Returns: if true it returns works where at least one author or has an . If false, it returns works where no authors have an ORCID ID. This is based on the orcid field within . Note that, sometimes, we assign ORCID using , so this does not necessarily mean that the work itself has ORCID information.
Get the works where at least one author has an ORCID ID:
Returns: works that have or lack a PubMed Central identifier () depending on the given value.
Get the works that have a pmcid:
``
Returns: works that have or lack a PubMed identifier (), depending on the given value.
Get the works that have a pmid:
``
This filter has been deprecated. See instead: .
Returns: works for which n-grams are available or unavailable, depending on the given value. N-grams power fulltext searches through the filter and the parameter.
Get the works that have n-grams:
Returns: works that have or lack , depending on the given value.
Get the works that have references:
Value: the for a given , where the source is
Returns: works where the chosen is the .
Value: the for an
Returns: works where the given institution ID is in
Get the works that have https://openalex.org/I205783295 in their host_organization_lineage:
Value: the for a
Returns: works where the given publisher ID is in
Get the works that have https://openalex.org/P4310320547 in their publisher_lineage:
MAG was a project by Microsoft Research to catalog all of the scholarly content on the internet. After it was discontinued in 2021, OpenAlex built upon the data MAG had accumulated, connecting and expanding it using . The methods that MAG used to identify and aggregate scholarly content were quite different from most of our other sources, and so the content inherited from MAG, especially works that we did not connect with data from other sources, can look different from other works. While it's great to have these MAG-only works available, you may not always want to include them in your results or analyses. This filter allows you to include or exclude any works that came from MAG and only MAG.
Get all MAG-only works:
Returns: works where the has at least one ISSN assigned.
Get the works that have an ISSN within the primary location:
Value: the for a
Returns: works where the given publisher ID is in
Get the works that have https://openalex.org/P4310320547 in their publisher_lineage:
Returns: works that have at least one which includes the given string. See the for details on the search algorithm used.
Get works with the words Department of Political Science, University of Amsterdam somewhere in at least one author's raw_affiliation_strings:
Value: the for a given work
Returns: works found in the given work's section.
Get works related to :
Value: the for a given , where the source is
Returns: works where the chosen exists within the .
You can use this to find works where authors are associated with your university, but the work is not part of the university's repository.
Get works that are available in the University of Michigan Deep Blue repository (OpenAlex ID: https://openalex.org/S4306400393)
Get works where at least one author is associated with the University of Michigan, but the works are not found in the University of Michigan Deep Blue repository
Learn which repositories have the most open access works
Returns: works whose (title) or abstract includes the given string; see the for details.
Get works with title or abstract mentioning "gum disease":
Returns: works with less than or equal to the given date.
This field requires an
Get works created on or after January 12th, 2023 (does not work without valid API key):
Returns: works with less than or equal to the given date.
Get works published on or before March 14th, 2001:
Value: a date, formatted as an date or date-time string (for example: "2020-05-17", "2020-05-17T15:30", or "2020-01-02T00:22:35.180390").
Returns: works with less than or equal to the given date.
This field requires an
Get works updated before or on January 12th, 2023 (does not work without valid API key):
Returns: works where the chosen version exists within the . If null, it returns works where no version is found in any of the locations.
Get works where a published version is available in at least one of the locations:
Get the author with the A5023888391:
That will return an object, describing everything OpenAlex knows about the author with that ID:
You can make up to 50 of these queries at once by .
Get the author with this ORCID: https://orcid.org/0000-0002-1298-3089:
You can use the full ID or a shorter Uniform Resource Name (URN) format like so:
You can use select to limit the fields that are returned in an author object. More details are .
Display only the id and display_name and orcid for an author object
Get counts of works by Open Access status:
It's best to before trying these out. It will show you how results are formatted, the number of results returned, and how to sort results.
The host_venue and alternate_host_venues properties have been deprecated in favor of and . The attributes host_venue and alternate_host_venues are no longer available in the Work object, and trying to access them in filters or group-bys will return an error.
(alias author.id)
(alias author.orcid)
(alias institutions.country_code)
(alias institutions.continent)
(alias institutions.id)
(alias institutions.ror)
(alias institutions.type)
(alias: is_corresponding): this marks whether or not we have corresponding author information for a given work
(DEPRECATED)
(alias is_oa)
(alias oa_status)
The best way to search for authors is to use the search query parameter, which searches the and the fields. Example:
Get works with the author name "Carl Sagan":
Names with diacritics are flexible as well. So a search for David Tarrago can return David Tarragó, and a search for David Tarragó can return David Tarrago. When searching with a diacritic, diacritic versions of the names are prioritized in order to honor the original form of the author's name. Read more about our handling of diacritics .
You can read more in the in the API Guide. It will show you how relevance score is calculated, how words are stemmed to improve search results, and how to do complex boolean searches.
You can also use search as a , by appending .search to the end of the property you are filtering for:
Get authors with the name "john smith" in the display_name:
You can also use the filter default.search, which works the same as using the .
Autocomplete authors with "ronald sw" in the display name:
Read more about .
The best way to search for works is to use the search query parameter, which searches across , , and . Example:
Get works with search term "dna" in the title, abstract, or fulltext:
Fulltext search is available for a subset of works, see for more details.
You can read more about search . It will show you how relevance score is calculated, how words are stemmed to improve search results, and how to do complex boolean searches.
You can use search as a , allowing you to fine-tune the fields you're searching over. To do this, you append .search to the end of the property you are filtering for:
Get works with "cubist" in the title:
You can also use the filter default.search, which works the same as using the .
These searches make use of stemming and stop-word removal. You can disable this for searches on titles and abstracts. Learn how to do this .
Find the ID of the related entity. For example, if you're interested in works associated with NYU, you could search the /institutions endpoint for that name: . Looking at the first result, you'll see that the OpenAlex ID for NYU is I57206974.
Use a with the /works endpoint to get all of the works: .
Autocomplete works with "tigers" in the title:
Read more about .
When you use the API to get a or , this is what's returned.
institution: a object
Integer: The total number that cite a work this author has created.
List: and for each of the last ten years, binned by year. To put it another way: each year, you can see how many works this author published, and how many times they got cited.
String: The date this Author object was created in the OpenAlex dataset, expressed as an date string.
openalex (String: this author's . Same as )
orcid (String: this author's . Same as )
scopus (String: this author's )
This field has been deprecated. Its replacement is .
List: List of Institution objects. This author's last known institutional affiliations. In this context "last known" means that we took all the author's , sorted them by publication date, and selected the most recent one. If there is only one affiliated institution for this author for the work, this will be a list of length 1; if there are multiple affiliations, they will all be included in the list.
Each item in the list is a object, and you can find more documentation on the page.
String: The for this author. ORCID is a global and unique ID for authors. This is the for authors.
2yr_mean_citedness Float: The 2-year mean citedness for this source. Also known as . We use the year prior to the current year for the citations (the numerator) and the two years prior to that for the citation-receiving publications (the denominator).
h_index Integer: The for this author.
i10_index Integer: The for this author.
String: The last time anything in this author object changed, expressed as an date string. This date is updated for any change at all, including increases in various counts.
Integer: The number of this this author has created.
This is updated a couple times per day. So the count may be slightly different than what's in works when viewed .
x_concepts will be deprecated and removed soon. We will be replacing this functionality with instead.
List: The concepts most frequently applied to works created by this author. Each is represented as a object, with one additional attribute:
The DehydratedAuthor is stripped-down object, with most of its properties removed to save weight. Its only remaining properties are:
When retrieving a list of works in the API, the authorships list within each work will be cut off at 100 authorships objects in order to keep things running well. When this happens the boolean value is_authors_truncated will be available and set to true. This affects a small portion of OpenAlex, as there are around 35,000 works with more than 100 authors. This limitation does not apply to the .
Example list of works with truncated authors
Work with all 249 authors available
Get authors that have an ORCID
It's best to before trying these out. It will show you how to combine filters and build an AND, OR, or negation query.
You can filter using these attributes of the Author entity object (click each one to view their documentation on the object page):
(alias: openalex)
(the author's scopus ID, as an integer)
(accepts float, null, !null, can use range queries such as < >)
(accepts integer, null, !null, can use range queries)
(accepts integer, null, !null, can use range queries)
(alias: concepts.id or concept.id) -- will be deprecated soon
To learn more about why we do it this way,
These filters aren't attributes of the , but they're included to address some common use cases:
This works the same as using the for Authors.
Returns: Authors whose contains the given string; see the for details.
Get authors named "tupolev":
Returns: authors that have or lack an , depending on the given value.
Get the authors that have an ORCID: ``
Value: a String with a valid
Get authors where the last known institution is located in Africa
Returns: works where at least one of the author's institutions is in the .
Get authors where the last known institution is located in the Global South
Get counts of authors by the last known institution continent: ``
It's best to before trying these out. It will show you how results are formatted, the number of results returned, and how to sort results.
Get all authors in OpenAlex
By default we return 25 results per page. You can change this default and through works with the per-page and page parameters:
Get the second page of authors results, with 50 results returned per page
You also can with the sort parameter:
Sort authors by cited by count, descending
Continue on to learn how you can and lists of authors.
You can use sample to get a random batch of authors. Read more about sampling and how to add a seed value .
Get 25 random authors
You can use select to limit the fields that are returned in a list of authors. More details are .
Display only the id and display_name and orcid within authors results
Get sources that have an ISSN
It's best to before trying these out. It will show you how to combine filters and build an AND, OR, or negation query
You can filter using these attributes of the Source entity object (click each one to view their documentation on the object page):
(alias: host_organization.id)
— Use this with a publisher ID to find works from that publisher and all of its children.
(alias: openalex)
— Requires exact match. Use the filter instead if you want to find works from a publisher and all of its children.
(accepts float, null, !null, can use range queries such as < >)
(accepts integer, null, !null, can use range queries)
(accepts integer, null, !null, can use range queries)
(alias: concepts.id or concept.id) -- will be deprecated soon
To learn more about why we do it this way,
These filters aren't attributes of the object, but they're included to address some common use cases:
Value: a String with a valid
Get sources that are associated with Asia
This works the same as using the for Sources.
Returns: sources with a containing the given string; see the for details.
Get sources with names containing "Neurology": ``
In most cases, you should use the parameter instead of this filter because it uses a better search algorithm.
Returns: sources that have or lack an , depending on the given value.
Get sources without ISSNs: ``
Returns: sources that are associated with the .
Get sources that are located in the Global South
We have created a page in our help docs to give you all the information you need about our author disambiguation including information about author IDs, how we disambiguate authors, and how you can curate your author profile. Go to to find out what you need to know!
Get the source with the S137773608:
That will return an object, describing everything OpenAlex knows about the source with that ID:
You can make up to 50 of these queries at once by .
Get the source with ISSN: 2041-1723:
You can use select to limit the fields that are returned in a source object. More details are .
Display only the id and display_name for a source object
Get a list of OpenAlex sources:
The for sources is ISSN-L, which is a special "main" ISSN assigned to every sources (sources tend to have multiple ISSNs). About 90% of sources in OpenAlex have an ISSN-L or ISSN.
Several sources may host the same work. OpenAlex reports both the primary host source (generally wherever the lives), and alternate host sources (like preprint repositories).
Sources are linked to works via the and properties.
Check out the , a Jupyter notebook showing how to use Python and the API to learn about all of the sources in a country.
ORCID
orcid
Scopus
scopus
twitter
Wikipedia
wikipedia
fulltext via n-grams
ISSN
issn
Fatcat
fatcat
Microsoft Academic Graph (MAG)
mag
Wikidata
wikidata
It's easy to get an institution from from the API with: /institutions/<entity_id>. Here's an example:
Get the institution with the OpenAlex ID I27837315:
https://api.openalex.org/institutions/I27837315
That will return an Institution object, describing everything OpenAlex knows about the institution with that ID:
You can make up to 50 of these queries at once by requesting a list of entities and filtering on IDs using OR syntax.
You can look up institutions using external IDs such as a ROR ID:
Get the institution with ROR ID https://ror.org/00cvxb145:
https://api.openalex.org/institutions/ror:https://ror.org/00cvxb145
Available external IDs for institutions are:
ROR
ror
Microsoft Academic Graph (MAG)
mag
Wikidata
wikidata
You can use select to limit the fields that are returned in an institution object. More details are here.
Display only the id and display_name for an institution object
https://api.openalex.org/institutions/I27837315?select=id,display_name
These are the fields in an institution object. When you use the API to get a single institution or lists of institutions, this is what's returned.
associated_institutionsList: Institutions related to this one. Each associated institution is represented as a dehydrated Institution object, with one extra property:
relationship (String): The type of relationship between this institution and the listed institution. Possible values: parent, child, and related.
Institution associations and the relationship vocabulary come from ROR's relationships.
cited_by_countInteger: The total number Works that cite a work created by an author affiliated with this institution. Or less formally: the number of citations this institution has collected.
country_codeString: The country where this institution is located, represented as an ISO two-letter country code.
counts_by_yearList: works_count and cited_by_count for each of the last ten years, binned by year. To put it another way: each year, you can see how many new works this institution put out, and how many times any work affiliated with this institution got cited.
Years with zero citations and zero works have been removed so you will need to add those in if you need them.
created_dateString: The date this Institution object was created in the OpenAlex dataset, expressed as an ISO 8601 date string.
display_nameString: The primary name of the institution.
display_name_acronymsList: Acronyms or initialisms that people sometimes use instead of the full display_name.
display_name_alternativesList: Other names people may use for this institution.
geoObject: A bunch of stuff we know about the location of this institution:
city (String): The city where this institution lives.
geonames_city_id (String): The city where this institution lives, as a GeoNames database ID.
region (String): The sub-national region (state, province) where this institution lives.
country_code (String): The country where this institution lives, represented as an ISO two-letter country code.
country (String): The country where this institution lives.
latitude (Float): Does what it says.
longitude (Float): Does what it says.
homepage_urlString: The URL for institution's primary homepage.
idString: The OpenAlex ID for this institution.
idsObject: All the external identifiers that we know about for this institution. IDs are expressed as URIs whenever possible. Possible ID types:
mag (Integer: this institution's Microsoft Academic Graph ID)
openalex (String: this institution's OpenAlex ID. Same as Institution.id)
ror (String: this institution's ROR ID. Same as Institution.ror)
wikipedia (String: this institution's Wikipedia page URL)
wikidata (String: this institution's Wikidata ID)
Many institution are missing one or more ID types (either because we don't know the ID, or because it was never assigned). Keys for null IDs are not displayed.
image_thumbnail_urlString: Same as image_url, but it's a smaller image.
is_super_systemBoolean: True if this institution is a "super system". This includes large university systems such as the University of California System (https://openalex.org/I2803209242), as well as some governments and multinational companies.
We have this special flag for these institutions so that we can exclude them from other institutions' lineage, which we do because these super systems are not generally relevant in group-by results when you're looking at ranked lists of institutions.
The list of institution IDs marked as super systems can be found in this file.
image_urlString: URL where you can get an image representing this institution. Usually this is hosted on Wikipedia, and usually it's a seal or logo.
internationalObject: The institution's display name in different languages. Derived from the wikipedia page for the institution in the given language.
display_name (Object)
key (String): language code in wikidata language code format. Full list of languages is here.
value (String): display_name in the given language
lineageList: OpenAlex IDs of institutions. The list will include this institution's ID, as well as any parent institutions. If this institution has no parent institutions, this list will only contain its own ID.
This information comes from ROR's relationships, specifically the Parent/Child relationships.
Super systems are excluded from the lineage. See is_super_system above.
repositoriesList: Repositories (Sources with type: repository) that have this institution as their host_organization
rolesList: List of role objects, which include the role (one of institution, funder, or publisher), the id (OpenAlex ID), and the works_count.
In many cases, a single organization does not fit neatly into one role. For example, Yale University is a single organization that is a research university, funds research studies, and publishes an academic journal. The roles property links the OpenAlex entities together for a single organization, and includes counts for the works associated with each role.
The roles list of an entity (Funder, Publisher, or Institution) always includes itself. In the case where an organization only has one role, the roles will be a list of length one, with itself as the only item.
rorString: The ROR ID for this institution. This is the Canonical External ID for institutions.
The ROR (Research Organization Registry) identifier is a globally unique ID for research organization. ROR is the successor to GRiD, which is no longer being updated.
summary_statsObject: Citation metrics for this institution
2yr_mean_citedness Float: The 2-year mean citedness for this source. Also known as impact factor. We use the year prior to the current year for the citations (the numerator) and the two years prior to that for the citation-receiving publications (the denominator).
h_index Integer: The h-index for this institution.
i10_index Integer: The i-10 index for this institution.
While the h-index and the i-10 index are normally author-level metrics and the 2-year mean citedness is normally a journal-level metric, they can be calculated for any set of papers, so we include them for institutions.
typeString: The institution's primary type, using the ROR "type" controlled vocabulary.
Possible values are: Education, Healthcare, Company, Archive, Nonprofit, Government, Facility, and Other.
updated_dateString: The last time anything in this Institution changed, expressed as an ISO 8601 date string. This date is updated for any change at all, including increases in various counts.
works_api_urlString: A URL that will get you a list of all the Works affiliated with this institution.
We express this as an API URL (instead of just listing the Works themselves) because most institutions have way too many works to reasonably fit into a single return object.
works_countInteger: The number of Works created by authors affiliated with this institution. Or less formally: the number of works coming out of this institution.
x_conceptsx_concepts will be deprecated and removed soon. We will be replacing this functionality with Topics instead.
List: The Concepts most frequently applied to works affiliated with this institution. Each is represented as a dehydrated Concept object, with one additional attribute:
score (Float): The strength of association between this institution and the listed concept, from 0-100.
DehydratedInstitution objectThe DehydratedInstitution is a stripped-down Institution object, with most of its properties removed to save weight. Its only remaining properties are:
These are the fields in a source object. When you use the API to get a single source or lists of sources, this is what's returned.
String: An abbreviated title obtained from the ISSN Centre.
Array: Alternate titles for this source, as obtained from the ISSN Centre and individual work records, like Crossref DOIs, that carry the source name as a string. These are commonly abbreviations or translations of the source's canonical name.
List: List of objects, each with price (Integer) and currency (String).
Article processing charge information, taken directly from DOAJ.
Integer: The source's article processing charge in US Dollars, if available from DOAJ.
The apc_usd value is calculated by taking the APC price (see apc_prices) with a currency of USD if it is available. If it's not available, we convert the first available value from apc_prices into USD, using recent exchange rates.
cited_by_countInteger: The total number of Works that cite a Work hosted in this source.
country_codeString: The country that this source is associated with, represented as an ISO two-letter country code.
counts_by_yearList: works_count and cited_by_count for each of the last ten years, binned by year. To put it another way: each year, you can see how many new works this source started hosting, and how many times any work in this source got cited.
If the source was founded less than ten years ago, there will naturally be fewer than ten years in this list. Years with zero citations and zero works have been removed so you will need to add those in if you need them.
created_dateString: The date this Source object was created in the OpenAlex dataset, expressed as an ISO 8601 date string.
display_nameString: The name of the source.
homepage_urlString: The starting page for navigating the contents of this source; the homepage for this source's website.
host_organizationString: The host organization for this source as an OpenAlex ID. This will be an Institution.id if the source is a repository, and a Publisher.id if the source is a journal, conference, or eBook platform (based on the type field).
host_organization_lineageList: OpenAlex IDs — See Publisher.lineage. This will only be included if the host_organization is a publisher (and not if the host_organization is an institution).
host_organization_nameString: The display_name from the host_organization, shown for convenience.
idString: The OpenAlex ID for this source.
idsObject: All the external identifiers that we know about for this source. IDs are expressed as URIs whenever possible. Possible ID types:
fatcat (String: this source's Fatcat ID)
issn (List: a list of this source's ISSNs. Same as Source.issn)
issn_l (String: this source's ISSN-L. Same as Source.issn_l)
mag (Integer: this source's Microsoft Academic Graph ID)
openalex (String: this source's OpenAlex ID. Same as Source.id)
wikidata (String: this source's Wikidata ID)
Many sources are missing one or more ID types (either because we don't know the ID, or because it was never assigned). Keys for null IDs are not displayed.
is_coreBoolean: Whether this source is identified as a "core source" by CWTS, used in the Open Leiden Ranking of universities around the world. The list of core sources can be found here.
is_in_doajBoolean: Whether this is a journal listed in the Directory of Open Access Journals (DOAJ).
is_oaBoolean: Whether this is currently fully-open-access source. This could be true for a preprint repository where everything uploaded is free to read, or for a Gold or Diamond open access journal, where all newly published Works are available for free under an open license.
We say "currently" because the status of a source can change over time. It's common for journals to "flip" to Gold OA, after which they may make only future articles open or also open their back catalogs. It's entirely possible for a source to say is_oa: true, but for an article from last year to require a subscription.
issnList: The ISSNs used by this source. Many publications have multiple ISSNs , so ISSN-L should be used when possible.
issn_lString: The ISSN-L identifying this source. This is the Canonical External ID for sources.
ISSN is a global and unique ID for serial publications. However, different media versions of a given publication (e.g., print and electronic) often have different ISSNs. This is why we can't have nice things. The ISSN-L or Linking ISSN solves the problem by designating a single canonical ISSN for all media versions of the title. It's usually the same as the print ISSN.
Array: Societies on whose behalf the source is published and maintained, obtained from our crowdsourced list. Thanks!
summary_statsObject: Citation metrics for this source
2yr_mean_citedness Float: The 2-year mean citedness for this source. Also known as impact factor. We use the year prior to the current year for the citations (the numerator) and the two years prior to that for the citation-receiving publications (the denominator).
h_index Integer: The h-index for this source.
i10_index Integer: The i-10 index for this source.
While the h-index and the i-10 index are normally author-level metrics, they can be calculated for any set of papers, so we include them for sources.
typeString: The type of source, which will be one of: journal, repository, conference, ebook platform, book series, metadata, or other.
updated_dateString: The last time anything in this Source object changed, expressed as an ISO 8601 date string. This date is updated for any change at all, including increases in various counts.
works_api_urlString: A URL that will get you a list of all this source's Works.
We express this as an API URL (instead of just listing the works themselves) because sometimes a source's publication list is too long to reasonably fit into a single Source object.
works_countInteger: The number of Works this source hosts.
x_conceptsx_concepts will be deprecated and removed soon. We will be replacing this functionality with Topics instead.
List: The Concepts most frequently applied to works hosted by this source. Each is represented as a dehydrated Concept object, with one additional attribute:
score (Float): The strength of association between this source and the listed concept, from 0-100.
DehydratedSource objectThe DehydratedSource is stripped-down Source object, with most of its properties removed to save weight. Its only remaining properties are:
You can group sources with the group_by parameter:
Get counts of sources by publisher: https://api.openalex.org/sources?group_by=publisher
Or you can group using one the attributes below.
It's best to read about group by before trying these out. It will show you how results are formatted, the number of results returned, and how to sort results.
/sources group_by attributeshost_organization (alias: host_organization.id)
host_organization_lineage (alias: host_organization.id)
Universities and other organizations to which authors claim affiliations
Institutions are universities and other organizations to which authors claim affiliations. OpenAlex indexes about 109,000 institutions.
Get a list of OpenAlex institutions:
https://api.openalex.org/institutions
The Canonical External ID for institutions is the ROR ID. All institutions in OpenAlex have ROR IDs.
Our information about institutions comes from metadata found in Crossref, PubMed, ROR, MAG, and publisher websites. In order to link institutions to works, we parse every affiliation listed by every author. These affiliation strings can be quite messy, so we’ve trained an algorithm to interpret them and extract the actual institutions with reasonably high reliability.
For a simple example: we will treat both “MIT, Boston, USA” and “Massachusetts Institute of Technology” as the same institution (https://ror.org/042nb2s44).
Institutions are linked to works via the works.authorships property.
Most papers use raw strings to enumerate author affiliations (eg "Univ. of Florida, Gainesville FL"). Parsing these determine the actual institution the author is talking about is nontrivial; you can find more information about how we do it, as well as downloading code, models, and test sets, here on GitHub.
Learn more about what you can do with institutions:
You can group institutions with the group_by parameter:
Get counts of institutions by country code: https://api.openalex.org/institutions?group_by=country_code
Or you can group using one the attributes below.
It's best to read about group by before trying these out. It will show you how results are formatted, the number of results returned, and how to sort results.
/institutions group_by attributesTopics assigned to works
Works in OpenAlex are tagged with Topics using an automated system that takes into account the available information about the work, including title, abstract, source (journal) name, and citations. There are around 4,500 Topics. Works are assigned topics using a model that assigns scores for each topic for a work. The highest-scoring topic is that work's primary_topic. We also provide additional highly ranked topics for works, in Work.topics.
To learn more about how OpenAlex topics work in general, see the Topics page at OpenAlex help pages.
For a detailed description of the methods behind OpenAlex Topics, see our paper: "OpenAlex: End-to-End Process for Topic Classification". The code and model are available at https://github.com/ourresearch/openalex-topic-classification.
Learn more about what you can do with topics:
You can get lists of institutions:
Get all institutions in OpenAlex https://api.openalex.org/institutions
Which returns a response like this:
By default we return 25 results per page. You can change this default and page through institutions with the per-page and page parameters:
Get the second page of institutions results, with 50 results returned per page https://api.openalex.org/institutions?per-page=50&page=2
You also can sort results with the sort parameter:
Sort institutions by cited by count, descending https://api.openalex.org/institutions?sort=cited_by_count:desc
Continue on to learn how you can filter and search lists of institutions.
You can use sample to get a random batch of institutions. Read more about sampling and how to add a seed value here.
Get 50 random institutions https://api.openalex.org/institutions?sample=50&per-page=50
You can use select to limit the fields that are returned in a list of institutions. More details are here.
Display only the id, ror, and display_name within institutions results
https://api.openalex.org/institutions?select=id,display_name,ror
These are the fields in a topic object. When you use the API to get a single topic or lists of topics, this is what's returned.
descriptionString: A description of this topic, generated by AI.
display_nameString: The English-language label of the topic.
domainObject: The ID and the name (display_name) for the domain of this topic. The domain is the highest level in the "domain, field, subfield, topic" system, which means it is the least granular. See the topics overview for more explanation and a diagram.
fieldObject: The ID and the name (display_name) for the field of this topic. The field is the second-highest level in the "domain, field, subfield, topic" system, which means it is the second-least granular. See the topics overview for more explanation and a diagram.
idString: The OpenAlex ID for this topic.
idsObject: All the external identifiers that we know about for this topic. IDs are expressed as URIs whenever possible. Possible ID types:
openalex (String: this topic's OpenAlex ID. Same as Topic.id)
wikipedia (String: this topic's Wikipedia page URL)
keywordsList: Keywords consisting of one or several words each, meant to represent the content of the papers in the topic. These keywords were generated as part of the AI model. For now, they are provided as-is, but we will be providing more support and documenting them more thoroughly.
subfieldObject: The ID and the name (display_name) for the subfield of this topic. The subfield is the third-highest level in the "domain, field, subfield, topic" system, which means it is the third-least granular. See the topics overview for more explanation and a diagram.
updated_dateString: The last time anything in this topic object changed, expressed as an ISO 8601 date string. This date is updated for any change at all, including increases in various counts.
works_countInteger: The number of works tagged with this topic.
You can filter institutions with the filter parameter:
Get institutions that are located in Canada https://api.openalex.org/institutions?filter=country_code:ca
It's best to read about filters before trying these out. It will show you how to combine filters and build an AND, OR, or negation query
/institutions attribute filtersYou can filter using these attributes of the Institution entity object (click each one to view their documentation on the Institution object page):
lineage: OpenAlex ID for an Institution
openalex: the OpenAlex ID of the Institution
repositories.host_organization: OpenAlex ID for an Institution
repositories.host_organization_lineage: OpenAlex ID for an Institution
repositories.id: the OpenAlex ID of a repository (a Source)
ror: the ROR ID of the Institution
summary_stats.2yr_mean_citedness (accepts float, null, !null, can use range queries such as < >)
summary_stats.h_index (accepts integer, null, !null, can use range queries)
summary_stats.i10_index (accepts integer, null, !null, can use range queries)
x_concepts.id (alias: concepts.id or concept.id) -- will be deprecated soon
/institutions convenience filtersThese filters aren't attributes of the Institution object, but they're included to address some common use cases:
continentValue: a String with a valid continent filter
Returns: institutions that are located in the chosen continent.
Get institutions that are located in South America https://api.openalex.org/institutions?filter=continent:south_america
default.searchValue: a search string
This works the same as using the search parameter for Institutions.
display_name.searchValue: a search string
Returns: institutions with a display_name containing the given string; see the search page for details.
Get institutions with names containing "technology":
https://api.openalex.org/institutions?filter=display_name.search:technology
In most cases, you should use the search parameter instead of this filter because it uses a better search algorithm.
has_rorValue: a Boolean (true or false)
Returns: institutions that have or lack a ROR ID, depending on the given value.
Get institutions without ROR IDs:
https://api.openalex.org/institutions?filter=has_ror:false
is_global_southValue: a Boolean (true or false)
Returns: institutions that are located in the Global South.
Get institutions that are located in the Global South https://api.openalex.org/institutions?filter=is_global_south:true
The best way to search for sources is to use the search query parameter, which searches across display_name, alternate_titles, and abbreviated_title. Example:
Search for the abbreviated version of the Journal of the American Chemical Society "jacs":
https://api.openalex.org/sources?search=jacs
You can read more about search here. It will show you how relevance score is calculated, how words are stemmed to improve search results, and how to do complex boolean searches.
You can also use search as a filter, allowing you to fine-tune the fields you're searching over. To do this, you append .search to the end of the property you are filtering for:
Get sources with "nature" in the title: https://api.openalex.org/sources?filter=display_name.search:nature
The following fields can be searched as a filter within sources:
You can also use the filter default.search, which works the same as using the search parameter.
You can autocomplete sources to create a very fast type-ahead style search function:
Autocomplete sources with "neuro" in the display_name: https://api.openalex.org/autocomplete/sources?q=neuro
This returns a list of sources with the publisher set as the hint:
Read more in the autocomplete page in the API guide.
The best way to search for institutions is to use the search query parameter, which searches the display_name, the display_name_alternatives, and the display_name_acronyms. Example:
Search institutions for San Diego State University:
https://api.openalex.org/institutions?search=san diego state university
You can read more about search here. It will show you how relevance score is calculated, how words are stemmed to improve search results, and how to do complex boolean searches.
You can also use search as a filter, allowing you to fine-tune the fields you're searching over. To do this, you append .search to the end of the property you are filtering for:
Get institutions with "florida" in the display_name:
https://api.openalex.org/institutions?filter=display_name.search:florida
The following field can be searched as a filter within institutions:
You can also use the filter default.search, which works the same as using the search parameter.
You can autocomplete institutions to create a very fast type-ahead style search function:
Autocomplete institutions with "harv" in the display_name:
https://api.openalex.org/autocomplete/institutions?q=harv
This returns a list of institutions with the institution location set as the hint:
Read more in the autocomplete page in the API guide.
Short words or phrases assigned to works using AI
Works in OpenAlex are tagged with Keywords using an automated system based on Topics.
cited_by_countInteger: The number of citations to works that have been tagged with this keyword. Or less formally: the number of citations to this keyword.
For example, if there are just two works tagged with this keyword and one of them has been cited 10 times, and the other has been cited 1 time, cited_by_count for this keyword would be 11.
created_datedisplay_nameString: The English-language label of the keyword.
idString: The OpenAlex ID for this keyword.
updated_dateworks_countInteger: The number of works tagged with this keyword.
It's easy to get a keyword from the API with: /keyword/<entity_id>. Here's an example:
You can get lists of keywords:
Which returns a response like this:
You can filter keywords with the filter parameter:
/keywords attribute filters/keywords convenience filtersdefault.searchValue: a search string
display_name.searchValue: a search string
You can group keywords with the group_by parameter:
Or you can group using one the attributes below.
Here are the fields in a publisher object. When you use the API to get a single publisher or lists of publishers, this is what's returned.
alternate_titlesList: A list of alternate titles for this publisher.
cited_by_countInteger: The number of citations to works that are linked to this publisher through journals or other sources.
For example, if a publisher publishes 27 journals and those 27 journals have 3,050 works, this number is the sum of the cited_by_count values for all of those 3,050 works.
country_codescounts_by_yearYears with zero citations and zero works have been removed so you will need to add those back in if you need them.
created_datedisplay_nameString: The primary name of the publisher.
hierarchy_levelInteger: The hierarchy level for this publisher. A publisher with hierarchy level 0 has no parent publishers. A hierarchy level 1 publisher has one parent above it, and so on.
idString: The OpenAlex ID for this publisher.
idsObject: All the external identifiers that we know about for this publisher. IDs are expressed as URIs whenever possible. Possible ID types:
ror String: this publisher's ROR ID
image_thumbnail_urlThis is usually a hotlink to a wikimedia image. You can change the width=300 parameter in the URL if you want a different thumbnail size.
image_urlString: URL where you can get an image representing this publisher. Usually this a hotlink to a Wikimedia image, and usually it's a seal or logo.
lineageparent_publisherString: An OpenAlex ID linking to the direct parent of the publisher. This will be null if the publisher's hierarchy_level is 0.
rolesIn many cases, a single organization does not fit neatly into one role. For example, Yale University is a single organization that is a research university, funds research studies, and publishes an academic journal. The roles property links the OpenAlex entities together for a single organization, and includes counts for the works associated with each role.
sources_api_urlString: An URL that will get you a list of all the sources published by this publisher.
We express this as an API URL (instead of just listing the sources themselves) because there might be thousands of sources linked to a publisher, and that's too many to fit here.
summary_statsObject: Citation metrics for this publisher
While the h-index and the i-10 index are normally author-level metrics and the 2-year mean citedness is normally a journal-level metric, they can be calculated for any set of papers, so we include them for publishers.
updated_dateworks_countInteger: The number of works published by this publisher.
Get all topics in OpenAlex
By default we return 25 results per page. You can change this default and through topics with the per-page and page parameters:
Get the second page of topics results, with 50 results returned per page
You also can with the sort parameter:
Sort topics by cited by count, descending
Continue on to learn how you can and lists of topics.
You can use sample to get a random batch of topics. Read more about sampling and how to add a seed value .
Get 10 random topics
You can use select to limit the fields that are returned in a list of topics. More details are .
Display only the id, display_name, and description within topics results
Get the topic with the C71924100:
That will return a object, describing everything OpenAlex knows about the topic with that ID:
You can make up to 50 of these queries at once by .
You can use select to limit the fields that are returned in a topic object. More details are .
Display only the id and display_name for a topic object
Get counts of topics by :
It's best to before trying these out. It will show you how results are formatted, the number of results returned, and how to sort results.
Get topics that are in the subfield "Epidemiology" (id: 2713)
It's best to before trying these out. It will show you how to combine filters and build an AND, OR, or negation query
You can filter using these attributes of the object (click each one to view their documentation on the Topic object page):
(alias: openalex)
These filters aren't attributes of the object, but they're included to address some common use cases:
This works the same as using the for Topics.
Returns: topics with a containing the given string; see the for details.
Get topics with display_name containing "artificial" and "intelligence":
In most cases, you should use the instead of this filter because it uses a better search algorithm.
Get a list of OpenAlex publishers:
Our publisher data is closely tied to the publisher information in Wikidata. So the for OpenAlex publishers is a Wikidata ID, and almost every publisher has one. Publishers are linked to sources through the field.
To learn more about how OpenAlex Keywords work in general, see .
These are the fields in a keyword object. When you use the API to get a or , this is what's returned.
String: The date this Keyword object was created in the OpenAlex dataset, expressed as an date string.
String: The last time anything in this keyword object changed, expressed as an date string. This date is updated for any change at all, including increases in various counts.
Get the keyword with the ID cardiac-imaging:
That will return a object, describing everything OpenAlex knows about the keyword with that ID:
You can make up to 50 of these queries at once by .
You can use select to limit the fields that are returned in a keyword object. More details are .
Display only the id and display_name for a keyword object
Get all keywords in OpenAlex
Get keywords that are in the subfield "Epidemiology" (id: 2713)
It's best to before trying these out. It will show you how to combine filters and build an AND, OR, or negation query
You can filter using these attributes of the object:
These filters aren't attributes of the object, but they're included to address some common use cases:
This works the same as using the for Keywords.
Returns: keywords with a containing the given string.
Get keywords with display_name containing "artificial" and "intelligence":
You can search for keywords using the search query parameter, which searches the fileds. For example:
Search keywords' display_name "artificial intelligence":
You can read more about search . It will show you how relevance score is calculated, how words are stemmed to improve search results, and how to do complex boolean searches.
Get counts of keywords by :
It's best to before trying these out. It will show you how results are formatted, the number of results returned, and how to sort results.
List: The countries where the publisher is primarily located, as an .
List: The values of and for each of the last ten years, binned by year. To put it another way: for every listed year, you can see how many new works are linked to this publisher, and how many times any work linked to this publisher was cited.
String: The date this Publisher object was created in the OpenAlex dataset, expressed as an date string.
openalex String: this publishers's
wikidata String: this publisher's
String: Same as , but it's a smaller image.
List: of publishers. The list will include this publisher's ID, as well as any parent publishers. If this publisher's hierarchy_level is 0, this list will only contain its own ID.
List: List of role objects, which include the role (one of institution, funder, or publisher), the id (), and the works_count.
The roles list of an entity (, , or ) always includes itself. In the case where an organization only has one role, the roles will be a list of length one, with itself as the only item.
2yr_mean_citedness Float: The 2-year mean citedness for this source. Also known as . We use the year prior to the current year for the citations (the numerator) and the two years prior to that for the citation-receiving publications (the denominator).
h_index Integer: The for this publisher.
i10_index Integer: The for this publisher.
String: The last time anything in this publisher object changed, expressed as an date string. This date is updated for any change at all, including increases in various counts.
The best way to search for topics is to use the search query parameter, which searches the , , and fields. Example:
Search topics' display_name and description for "artificial intelligence":
You can read more about search . It will show you how relevance score is calculated, how words are stemmed to improve search results, and how to do complex boolean searches.
You can also use search as a , allowing you to fine-tune the fields you're searching over. To do this, you append .search to the end of the property you are filtering for:
Get topics with "medical" in the display_name:
You can also use the filter default.search, which works the same as using the .
You can get lists of publishers:
Get all publishers in OpenAlex https://api.openalex.org/publishers
Which returns a response like this:
By default we return 25 results per page. You can change this default and page through publishers with the per-page and page parameters:
Get the second page of publishers results, with 50 results returned per page https://api.openalex.org/publishers?per-page=50&page=2
You also can sort results with the sort parameter:
Sort publishers by display name, descending https://api.openalex.org/publishers?sort=display_name:desc
Continue on to learn how you can filter and search lists of publishers.
You can use sample to get a random batch of publishers. Read more about sampling and how to add a seed value here.
Get 10 random publishers https://api.openalex.org/publishers?sample=10
You can use select to limit the fields that are returned in a list of publishers. More details are here.
Display only the id, display_name, and alternate_titles within publishers results
https://api.openalex.org/publishers?select=id,display_name,alternate_titles
You can group publishers with the group_by parameter:
Get counts of publishers by country_codes:
https://api.openalex.org/publishers?group\_by=country\_codes
Or you can group using one the attributes below.
It's best to read about group by before trying these out. It will show you how results are formatted, the number of results returned, and how to sort results.
/publishers group_by attributesOrganizations that fund research
Funders are organizations that fund research. OpenAlex indexes about 32,000 funders. Funder data comes from Crossref, and is enhanced with data from Wikidata and ROR.
Get a list of OpenAlex funders:
https://api.openalex.org/funders
Funders are connected to works through grants.
Learn more about what you can do with funders:
It's easy to get a publisher from from the API with: /publishers/<entity_id>. Here's an example:
Get the publisher with the OpenAlex ID P4310319965:
https://api.openalex.org/publishers/P4310319965
That will return a Publisher object, describing everything OpenAlex knows about the publisher with that ID:
You can make up to 50 of these queries at once by requesting a list of entities and filtering on IDs using OR syntax.
You can look up publishers using external IDs such as a Wikidata ID:
Get the publisher with Wikidata ID Q1479654: https://api.openalex.org/publishers/wikidata:Q1479654
Available external IDs for publishers are:
ROR
ror
Wikidata
wikidata
You can use select to limit the fields that are returned in a publisher object. More details are here.
Display only the id and display_name for a publisher object
https://api.openalex.org/publishers/P4310319965?select=id,display_name
You can filter publishers with the filter parameter:
Get publishers that are hierarchy level 0
https://api.openalex.org/publishers?filter=hierarchy\_level:0
It's best to read about filters before trying these out. It will show you how to combine filters and build an AND, OR, or negation query
/publishers attribute filtersYou can filter using these attributes of the Publisher entity object (click each one to view their documentation on the Publisher object page):
ids.openalex (alias: openalex)
ids.ror (alias: ror)
ids.wikidata (alias: wikidata)
lineage — Use this with a publisher ID to find that publisher and all of its children
summary_stats.2yr_mean_citedness (accepts float, null, !null, can use range queries such as < >)
summary_stats.h_index (accepts integer, null, !null, can use range queries)
summary_stats.i10_index (accepts integer, null, !null, can use range queries)
/publishers convenience filtersThese filters aren't attributes of the Publisher object, but they're included to address some common use cases:
continentValue: a String with a valid continent filter
Returns: publishers that are located in the chosen continent.
Get publishers that are located in South America https://api.openalex.org/publishers?filter=continent:south_america
default.searchValue: a search string
This works the same as using the search parameter for Publishers.
display_name.searchValue: a search string
Returns: publishers with a display_name containing the given string; see the search page for details.
Get publishers with names containing "elsevier":
https://api.openalex.org/publishers?filter=display_name.search:elsevier``
In most cases, you should use the search parameter instead of this filter because it uses a better search algorithm.
These are the fields in a funder object. When you use the API to get a single funder or lists of funders, this is what's returned.
alternate_titlesList: A list of alternate titles for this funder.
cited_by_countInteger: The total number Works that cite a work linked to this funder.
country_codeString: The country where this funder is located, represented as an ISO two-letter country code.
counts_by_yearList: The values of works_count and cited_by_count for each of the last ten years, binned by year. To put it another way: for every listed year, you can see how many new works are linked to this funder, and how many times any work linked to this funder was cited.
Years with zero citations and zero works have been removed so you will need to add those back in if you need them.
created_dateString: The date this Funder object was created in the OpenAlex dataset, expressed as an ISO 8601 date string.
descriptionString: A short description of this funder, taken from Wikidata.
display_nameString: The primary name of the funder.
grants_countInteger: The number of grants linked to this funder.
homepage_urlString: The URL for this funder's primary homepage.
idString: The OpenAlex ID for this funder.
idsObject: All the external identifiers that we know about for this funder. IDs are expressed as URIs whenever possible. Possible ID types:
crossref String: this funder's Crossref ID
doi String: this funder's DOI
openalex String: this funder's OpenAlex ID
ror String: this funder's ROR ID
wikidata String: this funder's Wikidata ID
image_thumbnail_urlString: Same as image_url, but it's a smaller image.
This is usually a hotlink to a wikimedia image. You can change the width=300 parameter in the URL if you want a different thumbnail size.
image_urlString: URL where you can get an image representing this funder. Usually this a hotlink to a Wikimedia image, and usually it's a seal or logo.
rolesList: List of role objects, which include the role (one of institution, funder, or publisher), the id (OpenAlex ID), and the works_count.
In many cases, a single organization does not fit neatly into one role. For example, Yale University is a single organization that is a research university, funds research studies, and publishes an academic journal. The roles property links the OpenAlex entities together for a single organization, and includes counts for the works associated with each role.
The roles list of an entity (Funder, Publisher, or Institution) always includes itself. In the case where an organization only has one role, the roles will be a list of length one, with itself as the only item.
summary_statsObject: Citation metrics for this funder
2yr_mean_citedness Float: The 2-year mean citedness for this source. Also known as impact factor. We use the year prior to the current year for the citations (the numerator) and the two years prior to that for the citation-receiving publications (the denominator).
h_index Integer: The h-index for this funder.
i10_index Integer: The i-10 index for this funder.
While the h-index and the i-10 index are normally author-level metrics and the 2-year mean citedness is normally a journal-level metric, they can be calculated for any set of papers, so we include them for funders.
updated_dateString: The last time anything in this funder object changed, expressed as an ISO 8601 date string. This date is updated for any change at all, including increases in various counts.
works_countInteger: The number of works linked to this funder.
You can get lists of funders:
Get all funders in OpenAlex https://api.openalex.org/funders
Which returns a response like this:
By default we return 25 results per page. You can change this default and page through funders with the per-page and page parameters:
Get the second page of funders results, with 50 results returned per page https://api.openalex.org/funders?per-page=50&page=2
You also can sort results with the sort parameter:
Sort funders by display name, descending https://api.openalex.org/funders?sort=display_name:desc
Continue on to learn how you can filter and search lists of funders.
You can use sample to get a random batch of funders. Read more about sampling and how to add a seed value here.
Get 10 random funders https://api.openalex.org/funders?sample=10
You can use select to limit the fields that are returned in a list of funders. More details are here.
Display only the id, display_name, and alternate_titles within funders results
https://api.openalex.org/funders?select=id,display_name,alternate_titles
You can filter funders with the filter parameter:
Get funders that are located in Canada https://api.openalex.org/funders?filter=country_code:ca
It's best to read about filters before trying these out. It will show you how to combine filters and build an AND, OR, or negation query
/funders attribute filtersYou can filter using these attributes of the Funder entity object (click each one to view their documentation on the Funder object page):
ids.openalex (alias: openalex)
ids.ror (alias: ror)
ids.wikidata (alias: wikidata)
summary_stats.2yr_mean_citedness (accepts float, null, !null, can use range queries such as < >)
summary_stats.h_index (accepts integer, null, !null, can use range queries)
summary_stats.i10_index (accepts integer, null, !null, can use range queries)
/funders convenience filtersThese filters aren't attributes of the Funder object, but they're included to address some common use cases:
continentValue: a String with a valid continent filter
Returns: funders that are located in the chosen continent.
Get funders that are located in South America
https://api.openalex.org/funders?filter=continent:south\_america
default.searchValue: a search string
This works the same as using the search parameter for Funders.
description.searchValue: a search string
Returns: funders with a description containing the given string; see the search page for details.
Get funders with description containing "health":
https://api.openalex.org/funders?filter=description.search:health
display_name.searchValue: a search string
Returns: funders with a display_name containing the given string; see the search page for details.
Get funders with names containing "health":
https://api.openalex.org/funders?filter=display_name.search:health
In most cases, you should use the search parameter instead of this filter because it uses a better search algorithm.
is_global_southValue: a Boolean (true or false)
Returns: funders that are located in the Global South.
Get funders that are located in the Global South https://api.openalex.org/funders?filter=is_global_south:true
You can group funders with the group_by parameter:
Get counts of funders by country_code:
https://api.openalex.org/funders?group_by=country_code
Or you can group using one the attributes below.
It's best to read about group by before trying these out. It will show you how results are formatted, the number of results returned, and how to sort results.
/funders group_by attributesIt's easy to get a funder from from the API with: /funders/<entity_id>. Here's an example:
Get the funder with the OpenAlex ID F4320332161:
https://api.openalex.org/funders/F4320332161
That will return a Funder object, describing everything OpenAlex knows about the funder with that ID:
You can make up to 50 of these queries at once by requesting a list of entities and filtering on IDs using OR syntax.
You can look up funders using external IDs such as a Wikidata ID:
Get the funder with Wikidata ID Q1479654:
https://api.openalex.org/funders/wikidata:Q390551
Available external IDs for funders are:
ROR
ror
Wikidata
wikidata
You can use select to limit the fields that are returned in a funder object. More details are here.
Display only the id and display_name for a funder object
https://api.openalex.org/funders/F4320332161?select=id,display_name
Where things are in the world
While geo is not a core entity within OpenAlex, geography is central to categorizing scholarly data. That's why OpenAlex uses United Nations data to divide the globe into continents and regions that makes filtering data easier.
Here are some ways you can filter and group by continents and the Global South.
Get institutions located in South America
https://api.openalex.org/institutions?filter=continent:south_america
Get works where at least one author's institution is located in the Global South
https://api.openalex.org/works?filter=institutions.is\_global\_south:true
Group highly-cited authors by their last known institution's continent
https://api.openalex.org/authors?group-by=last\_known\_institution.continent\&filter=cited\_by\_count:>100
Learn more about what you can do with geo:
The best way to search for publishers is to use the search query parameter, which searches the display_name and alternate_titles fields. Example:
Search publishers' display_name and alternate_titles for "springer":
https://api.openalex.org/publishers?search=springer
You can read more about search here. It will show you how relevance score is calculated, how words are stemmed to improve search results, and how to do complex boolean searches.
You can also use search as a filter, allowing you to fine-tune the fields you're searching over. To do this, you append .search to the end of the property you are filtering for:
Get publishers with "elsevier" in the display_name:
https://api.openalex.org/publishers?filter=display_name.search:elsevier
The following field can be searched as a filter within publishers:
You can also use the filter default.search, which works the same as using the search parameter.
You can autocomplete publishers to create a very fast type-ahead style search function:
Autocomplete publishers with "els" in the display_name:
https://api.openalex.org/autocomplete/publishers?q=els
This returns a list of publishers:
Read more in the autocomplete page in the API guide.
The best way to search for funders is to use the search query parameter, which searches the display_name, the alternate_titles, and the description fields. Example:
Search funders' display_name, alternate_titles, and description for "health":
https://api.openalex.org/funders?search=health
You can read more about search here. It will show you how relevance score is calculated, how words are stemmed to improve search results, and how to do complex boolean searches.
You can also use search as a filter, allowing you to fine-tune the fields you're searching over. To do this, you append .search to the end of the property you are filtering for:
Get funders with "florida" in the display_name:
https://api.openalex.org/funders?filter=display_name.search:florida
The following fields can be searched as a filter within funders:
You can also use the filter default.search, which works the same as using the search parameter.
You can autocomplete funders to create a very fast type-ahead style search function:
Autocomplete funders with "national sci" in the display_name:
https://api.openalex.org/autocomplete/funders?q=national+sci
This returns a list of funders with the funder location set as the hint:
Read more in the autocomplete page in the API guide.
You can filter Global South countries by using the boolean filter is_global_south in the following endpoints:
You can also group by the Global South:
To see country-by-country details for a geographic region, filter by region, then group by country_code.
Response:
ancestorscited_by_countInteger: The number citations to works that have been tagged with this concept. Or less formally: the number of citations to this concept.
For example, if there are just two works tagged with this concept and one of them has been cited 10 times, and the other has been cited 1 time, cited_by_count for this concept would be 11.
counts_by_yearYears with zero citations and zero works have been removed so you will need to add those back in if you need them.
created_datedescriptionString: A brief description of this concept.
display_nameString: The English-language label of the concept.
idString: The OpenAlex ID for this concept.
idsObject: All the external identifiers that we know about for this concept. IDs are expressed as URIs whenever possible. Possible ID types:
wikipedia (String: this concept's Wikipedia page URL)
Many concepts are missing one or more ID types (either because we don't know the ID, or because it was never assigned). Keys for null IDs are not displayed..
image_thumbnail_urlimage_urlString: URL where you can get an image representing this concept, where available. Usually this is hosted on Wikipedia.
internationaldisplay_name (Object)
value (String): display_name in the given language
levelrelated_conceptsscore (Float): The strength of association between this concept and the listed concept, on a scale of 0-100.
summary_statsObject: Citation metrics for this concept
While the h-index and the i-10 index are normally author-level metrics and the 2-year mean citedness is normally a journal-level metric, they can be calculated for any set of papers, so we include them for concepts.
updated_datewikidataAll OpenAlex concepts have a Wikidata ID, because all OpenAlex concepts are also Wikidata concepts.
works_api_urlString: An URL that will get you a list of all the works tagged with this concept.
We express this as an API URL (instead of just listing the works themselves) because there might be millions of works tagged with this concept, and that's too many to fit here.
works_countInteger: The number of works tagged with this concept.
DehydratedConcept object[`display_name`](concept-object.md#display\_name)
[`id`](concept-object.md#id)
[`level`](concept-object.md#level)
[`wikidata`](concept-object.md#wikidata)
Countries are mapped to continents using data from the . You can see the actual mapping used by the API .
Group institutions by continent
The Global South is a term used to identify regions within Latin America, Asia, Africa, and Oceania. Our source for this group of countries is the .
Get number of authors with last known institution in the Global South, by country
These are the original OpenAlex Concepts, which are being deprecated in favor of . We will continue to provide these Concepts for Works, but we will not be actively maintaining, updating, or providing support for these concepts. Unless you have a good reason to be relying on them, we encourage you to look into instead.
These are the fields in a concept object. When you use the API to get a or , this is what's returned.
List: List of concepts that this concept descends from, as objects. See the for more details on how the different layers of concepts work together.
List: The values of and for each of the last ten years, binned by year. To put it another way: for every listed year, you can see how many new works were tagged with this concept, and how many times any work tagged with this concept got cited.
String: The date this Concept object was created in the OpenAlex dataset, expressed as an date string.
mag (Integer: this concept's ID)
openalex (String: this concept's . Same as )
umls_cui (List: this concept's )
umls_aui (List: this concept's )
wikidata (String: this concept's . Same as )
String: Same as , but it's a smaller image.
Object: This concept's display name in many languages, derived from article titles on each language's wikipedia. See the for "Java Bytecode" for example source data.
key (String): language code in format. Full list of languages is .
Integer: The level in the concept tree where this concept lives. Lower-level concepts are more general, and higher-level concepts are more specific. has a level of 0; has a level of 5. Level 0 concepts have no ancestors and level 5 concepts have no descendants.
List: Concepts that are similar to this one. Each listed concept is a object, with one additional attribute:
2yr_mean_citedness Float: The 2-year mean citedness for this source. Also known as . We use the year prior to the current year for the citations (the numerator) and the two years prior to that for the citation-receiving publications (the denominator).
h_index Integer: The for this concept.
i10_index Integer: The for this concept.
String: The last time anything in this concept object changed, expressed as an date string. This date is updated for any change at all, including increases in various counts.
String: The for this concept. This is the for concepts.
The DehydratedConcept is stripped-down object, with most of its properties removed to save weight. Its only remaining properties are:
These are the original OpenAlex Concepts, which are being deprecated in favor of . We will continue to provide these Concepts for Works, but we will not be actively maintaining, updating, or providing support for these concepts. Unless you have a good reason to be relying on them, we encourage you to look into instead.
Get all the concepts used by OpenAlex:
The for OpenAlex concepts is the Wikidata ID, and each of our concepts has one, because all OpenAlex concepts are also Wikidata concepts.
Concepts are hierarchical, like a tree. There are 19 root-level concepts, and six layers of descendants branching out from them, containing about 65 thousand concepts all told. This concept tree is a modified version of .
You can view all the concepts and their position in the tree . About 85% of works are tagged with at least one concept (here's the ).
Each work is tagged with multiple concepts, based on the title, abstract, and the title of its host venue. The tagging is done using an automated classifier that was trained on MAG’s corpus; you can read more about the development and operation of this classifier in You can implement the classifier yourself using .
A score is available for each , showing the classifier's confidence in choosing that concept. However, when assigning a lower-level child concept, we also assign all of its parent concepts all the way up to the root. This means that some concept assignment scores will be 0.0. The tagger adds concepts to works written in different languages, but it is optimized for English.
Concepts are linked to works via the property, and to other concepts via the and properties.
These are the original OpenAlex Concepts, which are being deprecated in favor of . We will continue to provide these Concepts for Works, but we will not be actively maintaining, updating, or providing support for these concepts. Unless you have a good reason to be relying on them, we encourage you to look into instead.
Get all concepts in OpenAlex
By default we return 25 results per page. You can change this default and through concepts with the per-page and page parameters:
Get the second page of concepts results, with 50 results returned per page
You also can with the sort parameter:
Sort concepts by cited by count, descending
Continue on to learn how you can and lists of concepts.
You can use sample to get a random batch of concepts. Read more about sampling and how to add a seed value .
Get 10 random concepts
You can use select to limit the fields that are returned in a list of concepts. More details are .
Display only the id, display_name, and description within concepts results
Authors
/authors?filter=last_known_institution.continent:<continent>
Institutions
/institutions?filter=continent:<continent>
Works
/works?filter=institutions.continent:<continent>
Africa
africa
Antarctica
antarctica
Asia
asia
Europe
europe
North America
north_america
Oceania
oceania
South America
south_america
Authors
/authors?group-by=last_known_institution.continent
Institutions
/institutions?group-by=continent
Works
/works?group-by=institutions.continent
Authors
/authors?filter=last_known_institution.is_global_south:<boolean>
Institutions
/institutions?filter=is_global_south:<boolean>
Works
/works?filter=institutions.is_global_south:<boolean>
Authors
/authors?group-by=last_known_institution.is_global_south
Institutions
/institutions?group-by=is_global_south
Works
/works?group-by=institutions.is_global_south
These are the original OpenAlex Concepts, which are being deprecated in favor of Topics. We will continue to provide these Concepts for Works, but we will not be actively maintaining, updating, or providing support for these concepts. Unless you have a good reason to be relying on them, we encourage you to look into Topics instead.
You can filter concepts with the filter parameter:
Get concepts that are at level 0 (top level)
https://api.openalex.org/concepts?filter=level:0
It's best to read about filters before trying these out. It will show you how to combine filters and build an AND, OR, or negation query
/concepts attribute filtersYou can filter using these attributes of the Concept object (click each one to view their documentation on the Concept object page):
ids.openalex (alias: openalex)
summary_stats.2yr_mean_citedness (accepts float, null, !null, can use range queries such as < >)
summary_stats.h_index (accepts integer, null, !null, can use range queries)
summary_stats.i10_index (accepts integer, null, !null, can use range queries)
/concepts convenience filtersThese filters aren't attributes of the Concept object, but they're included to address some common use cases:
default.searchValue: a search string
This works the same as using the search parameter for Concepts.
display_name.searchValue: a search string
Returns: concepts with a display_name containing the given string; see the search page for details.
Get concepts with display_name containing "electrodynamics":
https://api.openalex.org/concepts?filter=display_name.search:electrodynamics
In most cases, you should use the search parameter instead of this filter because it uses a better search algorithm.
has_wikidataValue: a Boolean (true or false)
Returns: concepts that have or lack a Wikidata ID, depending on the given value. For now, all concepts in OpenAlex do have Wikidata IDs.
Get concepts without Wikidata IDs:
https://api.openalex.org/concepts?filter=has_wikidata:false
Get a single entity, based on an ID
This is a more detailed guide to single entities in OpenAlex. If you're just getting started, check out get a single work.
It's easy to get a singleton entity object from from the API:/<entity_name>/<entity_id>. Here's an example:
Get the work with the OpenAlex ID W2741809807: https://api.openalex.org/works/W2741809807
That will return a Work object, describing everything OpenAlex knows about the work with that ID. You can use IDs other than OpenAlex IDs, and you can also format the IDs in different ways. Read below to learn more.
You can make up to 50 of these queries at once by requesting a list of entities and filtering on IDs using OR syntax.
To get a single entity, you need a single unambiguous identifier, like an ORCID or an OpenAlex ID. If you've got an ambiguous identifier (like an author's name), you'll want to search instead.
The OpenAlex ID is the primary key for all entities. It's a URL shaped like this: https://openalex.org/<OpenAlex_key>. Here's a real-world example:
https://openalex.org/W2741809807
The OpenAlex ID has two parts. The first part is the Base; it's always https://openalex.org/. The second part is the Key; it's the unique primary key that identifies a given resource in our database.
The key starts with a letter; that letter tells you what kind of entity you've got: W(ork), A(uthor), S(ource), I(nstitution), C(oncept), P(ublisher), or F(under). The IDs are not case-sensitive, so w2741809807 is just as valid as W2741809807. So in the example above, the Key is W2741809807, and the W at the front tells us that this is a Work.
Because OpenAlex was launched as a replacement for Microsoft Academic Graph (MAG), OpenAlex IDs are designed to be backwards-compatible with MAG IDs, where they exist. To find the MAG ID, just take the first letter off the front of the unique part of the ID (so in the example above, the MAG ID is 2741809807). Of course this won't yield anything useful for entities that don't have a MAG ID.
At times we need to merge two Entities, effectively deleting one of them. This usually happens when we discover two Entities that represent the same real-world entity - for example, two Authors that are really the same person.
If you request an Entity using its OpenAlex ID, and that Entity has been merged into another Entity, you will be redirected to the Entity it has been merged into. For example, https://openalex.org/A5092938886 has been merged into https://openalex.org/A5006060960, so in the API the former will redirect to the latter:
Most clients will handle this transparently; you'll get the data for author A5006060960 without knowing the redirect even happened. If you have stored Entity ID lists and do notice the redirect, you might as well replace the merged-away ID to skip the redirect next time.
For each entity type, you can retrieve the entity using by any of the external IDs we support--not just the native OpenAlex IDs. So for example:
Get the work with this doi: https://doi.org/10.7717/peerj.4375:
https://api.openalex.org/works/https://doi.org/10.7717/peerj.4375
This works with DOIs, ISSNs, ORCIDs, and lots of other IDs...in fact, you can use any ID listed in an entity's ids property, as listed below:
Most of the external IDs OpenAlex supports are canonically expressed as URLs...for example, the canonical form of a DOI always starts with https://doi.org/. You can always use these URL-style IDs in the entity endpoints. Examples:
Get the institution with the ROR https://ror.org/02y3ad647 (University of Florida):
https://api.openalex.org/institutions/https://ror.org/02y3ad647
Get the author with the ORCID https://orcid.org/0000-0003-1613-5981 (Heather Piwowar):
https://api.openalex.org/authors/https://orcid.org/0000-0003-1613-5981
For simplicity and clarity, you may also want to express those IDs in a simpler, URN-style format, and that's supported as well; you just write the namespace of the ID, followed by the ID itself. Here are the same examples from above, but in the namespace:id format:
Get the institution with the ROR https://ror.org/02y3ad647 (University of Florida):
https://api.openalex.org/institutions/ror:02y3ad647
Get the author with the ORCID https://orcid.org/0000-0003-1613-5981 (Heather Piwowar):
https://api.openalex.org/authors/orcid:0000-0003-1613-5981
Finally, if you're using an OpenAlex ID, you can be even more succinct, and just use the Key part of the ID all by itself, the part that looks like w1234567:
Get the work with OpenAlex ID https://openalex.org/W2741809807: https://api.openalex.org/works/W2741809807
Every entity has an OpenAlex ID. Most entities also have IDs in other systems, too. There are hundreds of different ID systems, but we've selected a single external ID system for each entity to provide the Canonical External ID--this is the ID in the system that's been most fully adopted by the community, and is most frequently used in the wild. We support other external IDs as well, but the canonical ones get a privileged spot in the API and dataset.
These are the Canonical External IDs:
Works: DOI
Authors: ORCID
Sources: ISSN-L
Institutions: ROR ID
Concepts: Wikidata ID
Publishers: Wikidata ID
The full entity objects can get pretty unwieldy, especially when you're embedding a list of them in another object (for instance, a list of Concepts in a Work). For these cases, all the entities except Works have a dehydrated version. This is a stripped-down representation of the entity that carries only its most essential properties. These properties are documented individually on their respective entity pages.
\
These are the original OpenAlex Concepts, which are being deprecated in favor of Topics. We will continue to provide these Concepts for Works, but we will not be actively maintaining, updating, or providing support for these concepts. Unless you have a good reason to be relying on them, we encourage you to look into Topics instead.
It's easy to get a concept from the API with: /concepts/<entity_id>. Here's an example:
Get the concept with the OpenAlex ID C71924100:
https://api.openalex.org/concepts/C71924100
That will return a Concept object, describing everything OpenAlex knows about the concept with that ID:
You can make up to 50 of these queries at once by requesting a list of entities and filtering on IDs using OR syntax.
You can look up concepts using external IDs such as a wikidata ID:
Get the concept with wikidata ID Q11190: https://api.openalex.org/concepts/wikidata:Q11190
Available external IDs for concepts are:
Microsoft Academic Graph (MAG)
mag
Wikidata
wikidata
You can use select to limit the fields that are returned in a concept object. More details are here.
Display only the id and display_name for a concept object
https://api.openalex.org/concepts/C71924100?select=id,display_name
It's easy to get a list of entity objects from from the API:/<entity_name>. Here's an example:
Get a list of all the topics in OpenAlex:
https://api.openalex.org/topics
This query returns a meta object with details about the query, a results list of Topic objects, and an empty group_by list:
Listing entities is a lot more useful when you add parameters to page, filter, search, and sort them. Keep reading to learn how to do that.
These are the original OpenAlex Concepts, which are being deprecated in favor of Topics. We will continue to provide these Concepts for Works, but we will not be actively maintaining, updating, or providing support for these concepts. Unless you have a good reason to be relying on them, we encourage you to look into Topics instead.
You can group concepts with the group_by parameter:
Get counts of concepts by level:
https://api.openalex.org/concepts?group_by=level
Or you can group using one the attributes below.
It's best to read about group by before trying these out. It will show you how results are formatted, the number of results returned, and how to sort results.
/concepts group_by __ attributesYou can get a random result by using the string random where an ID would normally go. OMG that's so random! Each time you call this URL you'll get a different entity. Examples:
Get a random institution:
https://api.openalex.org/institutions/random
Get a random concept:
https://api.openalex.org/concepts/random
You can use select to choose top-level fields you want to see in a result.
Display id and display_name for a work
https://api.openalex.org/works/W2138270253?select=id,display_name
Read more about this feature here.
Filters narrow the list down to just entities that meet a particular condition--specifically, a particular value for a particular attribute.
A list of filters are set using the filter parameter, formatted like this: filter=attribute:value,attribute2:value2. Examples:
Get the works whose type is book:
https://api.openalex.org/works?filter=type:book
Get the authors whose name is Einstein:
https://api.openalex.org/authors?filter=display_name.search:einstein
Filters are case-insensitive.
For numerical filters, use the less-than (<) and greater-than (>) symbols to filter by inequalities. Example:
Get sources that host more than 1000 works:
https://api.openalex.org/sources?filter=works_count:>1000
Some attributes have special filters that act as syntactic sugar around commonly-expressed inequalities: for example, the from_publication_date filter on works. See the endpoint-specific documentation below for more information. Example:
Get all works published between 2022-01-01 and 2022-01-26 (inclusive):
https://api.openalex.org/works?filter=from_publication_date:2022-01-01,to_publication_date:2022-01-26
You can negate any filter, numerical or otherwise, by prepending the exclamation mark symbol (!) to the filter value. Example:
Get all institutions except for ones located in the US:
https://api.openalex.org/institutions?filter=country_code:!us
By default, the returned result set includes only records that satisfy all the supplied filters. In other words, filters are combined as an AND query. Example:
Get all works that have been cited more than once and are free to read:
https://api.openalex.org/works?filter=cited_by_count:>1,is_oa:true
To create an AND query within a single attribute, you can either repeat a filter, or use the plus symbol (+):
Get all the works that have an author from France and an author from the UK:
Using repeating filters: https://api.openalex.org/works?filter=institutions.country_code:fr,institutions.country_code:gb
Using the plus symbol (+): https://api.openalex.org/works?filter=institutions.country_code:fr+gb
Note that the plus symbol (+) syntax will not work for search filters, boolean filters, or numeric filters.
Use the pipe symbol (|) to input lists of values such that any of the values can be satisfied--in other words, when you separate filter values with a pipe, they'll be combined as an OR query. Example:
Get all the works that have an author from France or an author from the UK:
https://api.openalex.org/works?filter=institutions.country_code:fr|gb
This is particularly useful when you want to retrieve a many records by ID all at once. Instead of making a whole bunch of singleton calls in a loop, you can make one call, like this:
Get the works with DOI 10.1371/journal.pone.0266781 or with DOI 10.1371/journal.pone.0267149 (note the pipe separator between the two DOIs):
https://api.openalex.org/works?filter=doi:https://doi.org/10.1371/journal.pone.0266781|https://doi.org/10.1371/journal.pone.0267149
You can combine up to 100 values for a given filter in this way. You will also need to use the parameter per-page=100 to get all of the results per query. See our blog post for a tutorial.
You can use OR for values within a given filter, but not between different filters. So this, for example, doesn't work and will return an error:
Get either French works or ones published in the journal with ISSN 0957-1558:
https://api.openalex.org/works?filter=institutions.country_code:fr|primary_location.source.issn:0957-1558
The filters for each entity can be found here:
Use the ?sort parameter to specify the property you want your list sorted by. You can sort by these properties, where they exist:
display_name
cited_by_count
works_count
publication_date
relevance_score (only exists if there's a search filter active)
By default, sort direction is ascending. You can reverse this by appending :desc to the sort key like works_count:desc. You can sort by multiple properties by providing multiple sort keys, separated by commas. Examples:
All works, sorted by cited_by_count (highest counts first)
https://api.openalex.org/works?sort=cited_by_count:desc
All sources, in alphabetical order by title:
https://api.openalex.org/sources?sort=display_name
You can sort by relevance_score when searching:
Sort by year, then by relevance_score when searching for "bioplastics":
https://api.openalex.org/works?filter=display_name.search:bioplastics&sort=publication_year:desc,relevance_score:desc
An error is thrown if attempting to sort by relevance_score without a search query.
Sometimes instead of just listing entities, you want to group them into facets, and count how many entities are in each group. For example, maybe you want to count the number of Works by open access status. To do that, you call the entity endpoint, adding the group_by parameter. Example:
Get counts of works by type:
https://api.openalex.org/works?group_by=type
This returns a meta object with details about the query, and a group_by object with the groups you've asked for:
So from this we can see that the majority of works (202,814,957 of them) are type article, with another 21,250,659 book-chapter, and so forth.
You can group by most of the same properties that you can filter by, and you can combine grouping with filtering.
Each group object in the group_by list contains three properties:
keyValue: a string; the OpenAlex ID or raw value of the group_by parameter for members of this group. See details on key and key_display_name.
key_display_nameValue: a string; the display_name or raw value of the group_by parameter for members of this group. See details on key and key_display_name.
countValue: an integer; the number of entities in the group.
The "unknown" group is hidden by default. If you want to include this group in the response, add :include_unknown after the group-by parameter.
Group works by authorships.countries (unknown group hidden):
https://api.openalex.org/works?group_by=authorships.countries
Group works by authorships.countries (includes unknown group):
https://api.openalex.org/works?group_by=authorships.countries:include_unknown
key and key_display_nameIf the value being grouped by is an OpenAlex Entity, the key and key_display_name properties will be that Entity's id and display_name, respectively.
Group Works by Institution:
https://api.openalex.org/works?group_by=authorships.institutions.id
For one group, key is "https://openalex.org/I136199984" and key_display_name is "Harvard University".
Otherwise, key is the same as key_display_name; both are the raw value of the group_by parameter for this group.
Group Concepts by level:
https://api.openalex.org/concepts?group_by=level
For one group, both key and key_display_name are "3".
meta propertiesmeta.count is the total number of works (this will be all works if no filter is applied). meta.groups_count is the count of groups (in the current page).
If there are no groups in the response, meta.groups_count is null.
Due to a technical limitation, we can only report the number of groups in the current page, and not the total number of groups.
The maximum number of groups returned is 200. If you want to get more than 200 groups, you can use cursor pagination. This works the same as it does when getting lists of entities, so head over to the section on paging through lists of results to learn how.
Due to technical constraints, when paging, results are sorted by key, rather than by count.
You can use the /text API endpoint to tag your own free text with OpenAlex's "aboutness" assignments—topics, keywords, and concepts.
Accepts a title and optional abstract in the GET params or as a POST request. The results are straight from the model, with 0 values truncated.
Get OpenAlex Keywords for your text
https://api.openalex.org/text/keywords?title=type%201%20diabetes%20research%20for%20children
Get OpenAlex Topics for your text
https://api.openalex.org/text/topics?title=type%201%20diabetes%20research%20for%20children
Get OpenAlex Concepts for your text
https://api.openalex.org/text/concepts?title=type%201%20diabetes%20research%20for%20children
Get all of the above in one request
https://api.openalex.org/text?title=type%201%20diabetes%20research%20for%20children
Example response for that last one:
Queries are limited to between 20 and 2000 characters. The endpoints are rate limited to 1 per second and 1000 requests per day.
You can use select to limit the fields that are returned in results.
Display works with only the id, doi, and display_name returned in the results
https://api.openalex.org/works?select=id,doi,display\_name
The fields you choose must exist within the entity (of course). You can only select root-level fields.
So if we have a record like so:
You can choose to display id and open_access, but you will get an error if you try to choose open_access.is_oa.
You can use select fields when getting lists of entities or a single entity. It does not work with group-by or autocomplete.
First off: anyone can get the data for free. While the files are hosted on S3 and we’ll be using Amazon tools in these instructions, you don’t need an Amazon account.
Many thanks to the AWS Open Data program. They cover the data-transfer fees (about $70 per download!) so users don't have to.
Before you load the snapshot contents to your database, you’ll need to get the files that make it up onto your own computer. There are exceptions, like loading to redshift from s3 or using an ETL product like Xplenty with an S3 connector. If either of these apply to you, see if the snapshot data format is enough to get you started.
The easiest way to get the files is with the Amazon Web Services Command Line Interface (AWS CLI). Sample commands in this documentation will use the AWS CLI. You can find instructions for installing it on your system here: https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
You can also browse the snapshot files using the AWS console here: https://openalex.s3.amazonaws.com/browse.html. This browser and the CLI will work without an account.
This shell command will copy everything in the openalex S3 bucket to a local folder named openalex-snapshot. It'll take up roughly 300GB of disk space.
If you download the snapshot into an existing folder, you'll need to use the aws s3 sync --delete flag to remove files from any previous downloads. You can also remove the contents of destination folder manually. If you don't, you will see duplicate Entities that have moved from one file to another between snapshot updates.
The size of the snapshot will change over time. You can check the current size before downloading by looking at the output of:
You should get a file structure like this (edited for length - there are more objects in the actual bucket):
You can use sample to get a random list of up to 10,000 results.
Get 100 random works https://api.openalex.org/works?sample=100&per-page=100
Get 50 random works that are open access and published in 2021 https://api.openalex.org/works?filter=open_access.is_oa:true,publication_year:2021&sample=50&per-page=50
You can add a seed value in order to retrieve the same set of random records, in the same order, multiple times.
Get 20 random sources with a seed value https://api.openalex.org/sources?sample=20&seed=123
Depending on your query, random results with a seed value may change over time due to new records coming into OpenAlex.
The sample size is limited to 10,000 results.
You must provide a seed value when paging beyond the first page of results. Without a seed value, you might get duplicate records in your results.
You must use basic paging when sampling. Cursor pagination is not supported.
You can see executable examples of paging in this user-contributed Jupyter notebook!
Use the page query parameter to control which page of results you want (eg page=1, page=2, etc). By default there are 25 results per page; you can use the per-page parameter to change that to any number between 1 and 200.
Get the 2nd page of a list:
https://api.openalex.org/works?page=2
Get 200 results on the second page:
https://api.openalex.org/works?page=2&per-page=200
Basic paging only works to get the first 10,000 results of any list. If you want to see more than 10,000 results, you'll need to use cursor paging.
Cursor paging is a bit more complicated than basic paging, but it allows you to access as many records as you like.
To use cursor paging, you request a cursor by adding the cursor=* parameter-value pair to your query.
Get a cursor in order to start cursor pagination:
https://api.openalex.org/works?filter=publication_year:2020&per-page=100&cursor=*
The response to your query will include a next_cursor value in the response's meta object. Here's what it looks like:
To retrieve the next page of results, copy the meta.next_cursor value into the cursor field of your next request.
Get the next page of results using a cursor value:
https://api.openalex.org/works?filter=publication_year:2020&per-page=100&cursor=IlsxNjA5MzcyODAwMDAwLCAnaHR0cHM6Ly9vcGVuYWxleC5vcmcvVzI0ODg0OTk3NjQnXSI=
This second page of results will have a new value for meta.next_cursor. You'll use this new value the same way you did the first, and it'll give you the second page of results. To get all the results, keep repeating this process until meta.next_cursor is null and the results set is empty.
Besides using cursor paging to get entities, you can also use it in group_by queries.
Don't use cursor paging to download the whole dataset.
It's bad for you because it will take many days to page through a long list like /works or /authors.
It's bad for us (and other users!) because it puts a massive load on our servers.
Instead, download everything at once, using the OpenAlex snapshot. It's free, easy, fast, and you get all the results in same format you'd get from the API.
For most use cases, the REST API is your best option. However, you can also download (instructions here) and install a complete copy of the OpenAlex database on your own server, using the database snapshot. The snapshot consists of seven files (split into smaller files for convenience), with one file for each of our seven entity types. The files are in the JSON Lines format; each line is a JSON object, exactly the same as you'd get from our API. The properties of these JSON objects are documented in each entity's object section (for example, the Work object).
The snapshot is updated about once per month; you can read release notes for each new update here.
If you've worked with a dataset like this before, the snapshot data format may be all you need to get going. If not, read on.
The rest of this guide will tell you how to (a) download the snapshot and (b) upload it to your own database. We’ll cover two general approaches:
Flatten the records into a normalized schema in a relational database (we’ll use PostgreSQL) while preserving the relationships between objects.
We'll assume you're initializing a fresh snapshot. To keep it up to date, you'll have to take the information from Downloading updated Entities and generalize from the steps in the guide.
This is hard. Working with such a big and complicated dataset hardly ever goes according to plan. If it gets scary, try the REST API. In fact, try the REST API first. It can answer most of your questions and has a much lower barrier to entry.
There’s more than one way to do everything. We’ve tried to pick one reasonable default way to do each step, so if something doesn’t work in your environment or with the tools you have available, let us know.
Up next: the snapshot data format, downloading the data and getting it into your database.
Now that you have a copy of the OpenAlex data you can do one these:
upload it to a data warehouse
upload it to a relational database
We're working on making a collection of tutorials to demonstrate how to use OpenAlex to answer all sorts of questions. Check back often for more! Here's what we have currently
Turn the page - Use paging to collect all of the works from an author.
Monitoring Open Access publications for a given institution - Learn how to filter and group with the API.
What are the publication sources located in Japan? - Use the source entity to look at a country's publications over time.
Calculate the h-index for a given author - Use filtering, sorting, and paging to get citation counts and calculate the h-index, an author-level metric.
How are my institution's researchers collaborating with people around the globe? - Learn about institutions in OpenAlex while exploring the international research collaborations made by a university.
Getting started with OpenAlex Premium - Use your Premium API Key to download the latest updates from our API and keep your data in sync with ours.
Introduction to openalexR - In this R notebook, an accompaniment to the webinar on openalexR, you'll learn the basics of using the openalexR library to get data from OpenAlex.
The API is the primary way to get OpenAlex data. It's free and requires no authentication. The daily limit for API calls is 100,000 requests per user per day. For best performance, add your email to all API requests, like mailto=example@domain.com.
Get lists of entities — Learn how to use paging, filtering, and sorting
Get groups of entities — Group and count entities in different ways
Rate limits and authentication — Learn about joining the polite pool
Tutorials — Hands-on examples with code
There are several third-party libraries you can use to get data from OpenAlex:
openalexR (R)
OpenAlex2Pajek (R)
KtAlex (Kotlin)
PyAlex (Python)
diophila (Python)
OpenAlexAPI (Python)
If you're looking for a visual interface, you can also check out the free VOSviewer, which lets you make network visualizations based on OpenAlex data:
These are the original OpenAlex Concepts, which are being deprecated in favor of Topics. We will continue to provide these Concepts for Works, but we will not be actively maintaining, updating, or providing support for these concepts. Unless you have a good reason to be relying on them, we encourage you to look into Topics instead.
The best way to search for concepts is to use the search query parameter, which searches the display_name and description fields. Example:
Search concepts' display_name and description for "artificial intelligence":
https://api.openalex.org/concepts?search=artificial intelligence
You can read more about search here. It will show you how relevance score is calculated, how words are stemmed to improve search results, and how to do complex boolean searches.
You can also use search as a filter, allowing you to fine-tune the fields you're searching over. To do this, you append .search to the end of the property you are filtering for:
Get concepts with "medical" in the display_name:
https://api.openalex.org/concepts?filter=display_name.search:medical
The following field can be searched as a filter within concepts:
You can also use the filter default.search, which works the same as using the search parameter.
You can autocomplete concepts to create a very fast type-ahead style search function:
Autocomplete concepts with "comp" in the display_name:
https://api.openalex.org/autocomplete/concepts?q=comp
This returns a list of concepts with the description set as the hint:
Read more in the autocomplete page in the API guide.
The API is rate-limited. The limits are:
max 100,000 calls every day, and also
max 10 requests every second.
If you hit the API more than 100k times in a day or more than 10 in a second, you'll get 429 errors instead of useful data.
Are those rate limits too low for you? No problem! We can raise those limits as high as you need if you subscribe to our Premium plan. And if you're an academic researcher we can likely do it for free; just drop us a line at support@openalex.org.
Are you scrolling through a list of entities, calling the API for each? You can go way faster by squishing 50 requests into one using our OR syntax. Here's a tutorial showing how.
The OpenAlex API doesn't require authentication. However, it is helpful for us to know who's behind each API call, for two reasons:
It allows us to get in touch with the user if something's gone wrong--for instance, their script has run amok and we've needed to start blocking or throttling their usage.
It lets us report back to our funders, which helps us keep the lights on.
Like Crossref (whose approach we are shamelessly stealing), we separate API users into two pools, the polite pool and the common pool. The polite pool has more consistent response times. It's where you want to be.
To get into the polite pool, you just have to give us an email where we can contact you. You can give us this email in one of two ways:
Add the mailto=you@example.com parameter in your API request, like this: https://api.openalex.org/works?mailto=you@example.com
Add mailto:you@example.com somewhere in your User-Agent request header.
You don't need an API key to use OpenAlex. However, premium users do get an API key, which grants higher API limits and enables the use of special filters like from_updated_date. Using the API key is simple; just add it to your URL using the api_key param.
Get a list of all works, using the api key 424242:
https://api.openalex.org/works?api_key=424242
Because the API is all GET requests without fancy authentication, you can view any request in your browser. This is a very useful and pleasant way to explore the API and debug scripts; we use it all the time.
However, this is much nicer if you install an extension to pretty-print the JSON; JSONVue (Chrome) and JSONView (Firefox) are popular, free choices. Here's what an API response looks like with one of these extensions enabled:
The autocomplete endpoint lets you add autocomplete or typeahead components to your applications, without the overhead of hosting your own API endpoint.
Each endpoint takes a string, and (very quickly) returns a list of entities that match that string.
Here's an example of an autocomplete component that lets users quickly select an institution:
This is the query behind that result: https://api.openalex.org/autocomplete/institutions?q=flori
The autocomplete endpoint is very fast; queries generally return in around 200ms. If you'd like to see it in action, we're using a slightly-modified version of this endpoint in the OpenAlex website here: https://explore.openalex.org/
The format for requests is simple: /autocomplete/<entity_type>?q=<query>
entity_type (optional): the name of one of the OpenAlex entities: works, authors, sources, institutions, concepts, publishers, or funders.
query: the search string supplied by the user.
You can optionally filter autocomplete results.
Each request returns a response object with two properties:
meta: an object with information about the request, including timing and results count
results: a list of up to ten results for the query, sorted by citation count. Each result represents an entity that matched against the query.
Each object in the results list includes these properties:
id (string): The OpenAlex ID for this result entity.
external_id (string): The Canonical External ID for this result entity.
display_name (string): The entity's display_name property.
entity_type (string): The entity's type: author, concept, institution, source, publisher, funder, or work.
cited_by_count (integer): The entity's cited_by_count property. For works this is simply the number of incoming citations. For other entities, it's the sum of incoming citations for all the works linked to that entity.
works_count (integer): The number of works associated with the entity. For entity type work it's always null.
hint: Some extra information that can help identify the right item. Differs by entity type.
hint propertyResult objects have a hint property. You can show this to users to help them identify which item they're selecting. This is particularly helpful when the display_name values of different results are the same, as often happens when autocompleting an author entity--a user who types in John Smi is going to see a lot of identical-looking results, even though each one is a different person.
The content of the hint property varies depending on what kind of entity you're looking up:
Work: The work's authors' display names, concatenated. e.g. "R. Alexander Pyron, John J. Wiens"
Author: The author's last known institution, e.g. "University of North Carolina at Chapel Hill, USA"
Source: The host_organization, e.g. "Oxford University Press"
Institution: The institution's location, e.g. "Gainesville, USA"
Concept: The Concept's description, e.g. "the study of relation between plant species and genera"
Canonical External IDs and OpenAlex IDs are detected within autocomplete queries and matched to the appropriate record if it exists. For example:
The query https://api.openalex.org/autocomplete?q=https://orcid.org/0000-0002-7436-3176 will search for the author with ORCID ID https://orcid.org/0000-0002-7436-3176 and return 0 records if it does not exist.
The query https://api.openalex.org/autocomplete/sources?q=S49861241 will search for the source with OpenAlex ID https://openalex.org/S49861241 and return 0 records if it does not exist.
All entity filters and search queries can be added to autocomplete and work as expected, like:
https://api.openalex.org/autocomplete/works?filter=publication_year:2010&search=frogs&q=greenhou
Here are the details on where the OpenAlex data lives and how it's structured.
The data files are gzip-compressed JSON Lines, one row per entity.
Records are partitioned by updated_date. Within each entity type prefix, each object (file) is further prefixed by this date. For example, if an Author has an updated_date of 2021-12-30 it will be prefixed/data/authors/updated_date=2021-12-30/.
If you're initializing a fresh snapshot, the updated_date partitions aren't important yet. You need all the entities, so for Authors you would get /data/authors/*/*.gz
There are multiple objects under each updated_date partition. Each is under 2GB.
The manifest file is JSON (in redshift manifest format) and lists all the data files for each object type - /data/works/manifest lists all the works.
The gzip-compressed snapshot takes up about 330 GB and decompresses to about 1.6 TB.
The structure of each entity type is documented here: Work, Author, Source, Institution, Concept, and Publisher.
We have recently added folders for new entities topics, fields, subfields, and domains, and we will be adding others soon. This documentation will soon be updated to reflect these changes.
This is a screenshot showing the "leaf" nodes of one entity type, updated date folder. You can also click around the browser links above to get a sense of the snapshot's structure.
Once you have a copy of the snapshot, you'll probably want to keep it up to date. The updated_date partitions make this easy, but the way they work may be unfamiliar. Unlike a set of dated snapshots that each contain the full dataset as of a certain date, each partition contains the records that last changed on that date.
If we imagine launching OpenAlex on 2021-12-30 with 1000 Authors, each being newly created on that date, /data/authors/ looks like this:
If, on 2022-01-04, we made changes to 50 of those Authors, they would come out of one of the files in /data/authors/updated_date=2021-12-30 and go into one in /data/authors/updated_date=2022-01-04:
If we also discovered 50 new Authors, they would go in that same partition, so the totals would look like this:
So if you made your copy of the snapshot on 2021-12-30, you would only need to download /data/authors/updated_date=2022-01-04 to get everything that was changed or added since then.
To update a snapshot copy that you created or updated on date X, insert or update the records in objects where updated_date > X.
You never need to go back for a partition you've already downloaded. Anything that changed isn't there anymore, it's in a new partition.
At the time of writing, these are the Author partitions and the number of records in each (in the actual dataset):
updated_date=2021-12-30/ - 62,573,099
updated_date=2022-12-31/ - 97,559,192
updated_date=2022-01-01/ - 46,766,699
updated_date=2022-01-02/ - 1,352,773
This reflects the creation of the dataset on 2021-12-30 and 145,678,664 combined updates and inserts since then - 1,352,773 of which were on 2022-01-02. Over time, the number of partitions will grow. If we make a change that affects all records, the partitions before the date of the change will disappear.
See Merged Entities for an explanation of what Entity merging is and why we do it.
Alongside the folders for the six Entity types - work, author, source, institution, concept, and publisher - you'll find a seventh folder: merged_ids. Within this folder you'll find the IDs of Entities that have been merged away, along with the Entity IDs they were merged into.
Keep in mind that merging an Entity ID is a way of deleting the Entity while persisting its ID in OpenAlex. In practice, you can just delete the Entity it belongs to. It's not necessary to keep track of the date or which entity it was merged into.
Merge operations are separated into files by date. Each file lists the IDs of Entities that were merged on that date, and names the Entities they were merged into.
For example, data/merged_ids/authors/2022-06-07.csv.gz begins:
When processing this file, all you need to do is delete A2257618939. The effects of merging these authors, like crediting A2208157607 with their Works, are already reflected in the affected Entities.
Like the Entities' updated_date partitions, you only ever need to download merged_ids files that are new to you. Any later merges will appear in new files with later dates.
manifest fileWhen we start writing a new updated_date partition for an entity, we'll delete that entity's manifest file. When we finish writing the partition, we'll recreate the manifest, including the newly-created objects. So if manifest is there, all the entities are there too.
The file is in redshift manifest format. To use it as part of the update process for an Entity type (we'll keep using Authors as an example):
Download s3://openalex/data/authors/manifest.
Get the file list from the url property of each item in the entries list.
Download any objects with an updated_date you haven't seen before.
Download s3://openalex/data/authors/manifest again. If it hasn't changed since (1), no records moved around and any date partitions you downloaded are valid.
Decompress the files you downloaded and parse one JSON Author per line. Insert or update into your database of choice, using each entity's ID as a primary key.
If you’ve worked with dataset like this before and have a toolchain picked out, this may be all you need to know. If you want more detailed steps, proceed to download the data.
Compared to using a data warehouse, loading the dataset into a relational database takes more work up front but lets you write simpler queries and run them on less powerful machines. One important caveat is that this is a lot of data, and exploration will be very slow in most relational databases.
By using a relational database, you trade flexibility for efficiency in certain selected operations. The tables, columns, and indexes we have chosen in this guide represent only one of many ways the entity objects could be stored. It may not be the best way to store them given the queries you want to run. Some queries will be fast, others will be painfully slow.
We’re going to use PostgreSQL as an example and skip the database server setup itself. We’ll assume you have a working postgres 13+ installation on which you can create schemas and tables and run queries. With that as a starting point, we'll take you through these steps:
Define the tables the data will be stored in and some key relationships between them (the "schema").
Convert the JSON Lines files you downloaded to CSV files that can be read by the database application. We'll flatten them to fit a hierarchical database model.
Load the CSV data into to the tables you created.
Run some queries on the data you loaded.
Running this SQL on your database (in the psql client, for example) will initialize a schema for you.
Run it and you'll be set up to follow the next steps. To show you what it's doing, we'll explain some excerpts here, using the concept entity as an example.
SQL in this section isn't anything additional you need to run. It's part of the schema we already defined in the file above.
The key thing we're doing is "flattening" the nested JSON data. Some parts of this are easy. Concept.id is just a string, so it goes in a text column called "id":
But Concept.related_concepts isn't so simple. You could store the JSON array intact in a postgres JSON or JSONB column, but you would lose much of the benefit of a relational database. It would be hard to answer questions about related concepts with more than one degree of separation, for example. So we make a separate table to hold these relationships:
We can preserve score in this relationship table and look up any other attributes of the dehydrated related concepts in the main table concepts. Creating indexes on concept_id and related_concept_id lets us look up concepts on both sides of the relationship quickly.
This python script will turn the JSON Lines files you downloaded into CSV files that can be copied to the the tables you created in step 1.
This script assumes your downloaded snapshot is in openalex-snapshot and you've made a directory csv-files to hold the CSV files.
Edit SNAPSHOT_DIR and CSV_DIR at the top of the script to read or write the files somewhere else.
This script has only been tested using python 3.9.5.
Copy the script to the directory above your snapshot (if the snapshot is in /home/yourname/openalex/openalex-snapshot/, name it something like /home/yourname/openalex/flatten-openalex-jsonl.py)
run it like this:
This script is slow. Exactly how slow depends on the machine you run it on, but think hours, not minutes.
If you're familiar with python, there are two big improvements you can make:
Run flatten_authors and flatten_works at the same time, either by using threading in python or just running two copies of the script with the appropriate lines commented out.
Flatten multiple .gz files within each entity type at the same time. This means parallelizing the for jsonl_file_name ... loop in each flatten_ function and writing multiple CSV files per entity type.
You should now have a directory full of nice, flat CSV files:
Now we run one postgres copy command to load each CSV file to its corresponding table. Each command looks like this:
This script will run all the copy commands in the right order. Here's how to run it:
Copy it to the same place as the python script from step 2, right above the folder with your CSV files.
Set the environment variable OPENALEX_SNAPSHOT_DB to the connection URI for your database.
If your CSV files aren't in csv-files, replace each occurence of 'csv-files/' in the script with the correct path.
Run it like this (from your shell prompt)
or like this (from psql)
There are a bunch of ways you can do this - just run the copy commands from the script above in the right order in whatever client you're familiar with.
Now you have all the OpenAlex data in your database and can run queries in your favorite client.
Here’s a simple one, getting the OpenAlex ID and OA status for each work:
You'll get results like this (truncated, the actual result will be millions of rows):
closed
gold
bronze
Here’s an example of a more complex query - finding the author with the most open access works of all time:
We get the one row we asked for:
https://openalex.org/A2798520857
3297
Checking out https://api.openalex.org/authors/A2798520857, we see that this is Ashok Kumar at Manipal University Jaipur. We could also have found this directly in the query, through openalex.authors.
This is a diagram of one possible schema for storing the OpenAlex data in a relational database. It's the one used in our examples here, but may not be the best one for the ways you'll use the dataset.
(click to embiggen)
Please tell us about it using this form on our help page.
In many data warehouse and document store applications, you can load the OpenAlex entities as-is and query them directly. We’ll use BigQuery as an example here. (Elasticsearch docs coming soon). To follow along you’ll need the Google Cloud SDK. You’ll also need a Google account that can make BigQuery tables that are, well… big. Which means it probably won’t be free.
We'll show you how to do this in 4 steps:
Create a BigQuery Project and Dataset to hold your tables
Create the tables that will hold your entity JSON records
Copy the data files to the tables you created
Run some queries on the data you loaded
This guide will have you load each entity to a single text column, then use BigQuery's JSON functions to parse them when you run your queries. This is convenient but inefficient since each object has to be parsed every time you run a query.
This project, kindly shared by @DShvadron, takes a more efficient approach: https://github.com/DrorSh/openalex_to_gbq
Separating the Entity data into multiple columns takes more work up front but lets you write queries that are faster, simpler, and often cheaper.
Snowflake users can connect to a ready-to-query data set on the marketplace, helpfully maintained by Util - https://app.snowflake.com/marketplace/listing/GZT0ZOMX4O7
In BigQuery, you need a Project and Dataset to hold your tables. We’ll call the project “openalex-demo” and the dataset “openalex”. Follow the linked instructions to create the Project, then create the dataset inside it:
Dataset 'openalex-demo:openalex' successfully created
Now, we’ll create tables inside the dataset. There will be 5 tables, one for each entity type. Since we’re using JSON, each table will have just one text column named after the table.
Table 'openalex-demo:openalex.works' successfully created.
Table 'openalex-demo:openalex.authors' successfully created
and so on for sources, institutions, concepts, and publishers.
We’ll load each table’s data from the JSON Lines files we downloaded earlier. For works, the files were:
openalex-snapshot/data/works/updated_date=2021-12-28/0000_part_00.gz
openalex-snapshot/data/works/updated_date=2021-12-28/0001_part_00.gz
Here’s a command to load one works file (don’t run it yet):
See the full documentation for the bq load command here: https://cloud.google.com/bigquery/docs/reference/bq-cli-reference#bq_load
This part of the command may need some explanation:
--source_format=CSV -F '\t' --schema 'work:string'
Bigquery is expecting multiple columns with predefined datatypes (a “schema”). We’re tricking it into accepting a single text column (--schema 'work:string') by specifying CSV format (--source_format=CSV) with a column delimiter that isn’t present in the file (-F '\t') (\t means “tab”).
bq load can only handle one file at a time, so you must run this command once per file. But remember that the real dataset will have many more files than this example does, so it's impractical to copy, edit, and rerun the command each time. It's easier to handle all the files in a loop, like this:
This step is slow. How slow depends on your upload speed, but for Author and Work we're talking hours, not minutes.
You can speed this up by using parallel or other tools to run multiple upload commands at once. If you do, watch out for errors caused by hitting BigQuery quota limits.
Do this once per entity type, substituting each entity name for work/works as needed. When you’re finished, you’ll have five tables that look like this:
Now you have the all the OpenAlex data in a place where you can do anything you want with it using BigQuery JSON functions through bq query or the BigQuery console.
Here’s a simple one, extracting the OpenAlex ID and OA status for each work:
It will give you a list of IDs (this is a truncated sample, the real result will be millions of rows):
TRUE
FALSE
FALSE
You can run queries like this directly in your shell:
But even simple queries are hard to read and edit this way. It’s better to write them in a file than directly on the command line. Here’s an example of a slightly more complex query - finding the author with the most open access works of all time:
We get one result:
https://openalex.org/A2798520857
3297
Checking out https://api.openalex.org/authors/A2798520857, we see that this is Ashok Kumar at Manipal University Jaipur.
Yes!* The work associated with ID W1234 will keep the ID W1234.
When we find duplicated works, authors, etc that already have assigned IDs, we merge them. Merged entities will redirect to the proper entity in the API. In the data snapshot, there is a directory which lists the IDs that have been merged.
Yes. We automatically gather and normalize author affiliations from both structured and unstructured sources.
Web crawls
Our dataset is still very young, so there's not a lot of systematic research comparing OpenAlex to peer databases like MAG, Scopus, Dimensions, etc. We're currently working on publishing some research like that ourselves. Our initial finding are very encouraging...we believe OpenAlex is already comparable in coverage and accuracy to the more established players--but OpenAlex is 100% open data, built on 100% open-source code. We think that's a really important feature. We will also continue improving the data quality in the days, weeks, months, and years ahead!
search parameterThe search query parameter finds results that match a given text search. Example:
To disable stemming and the removal of stop words for searches on titles and abstracts, you can add .no_stem to the search filter. So, for example, if you want to search for "surgery" and not get "surgeries" too:
This allows you to craft complex queries using those boolean operators along with parentheses and quotation marks. Surrounding a phrase with quotation marks will search for an exact match of that phrase, after stemming and stop-word removal (be sure to use double quotation marks — "). Using parentheses will specify order of operations for the boolean operators. Words that are not separated by one of the boolean operators will be interpreted as AND.
When you use search, each returned entity in the results lists gets an extra property called relevance_score, and the list is by default sorted in descending order of relevance_score. The relevance_score is based on text similarity to your search term. It also includes a weighting term for citation counts: more highly-cited entities score higher, all else being equal.
If you search for a multiple-word phrase, the algorithm will treat each word separately, and rank results higher when the words appear close together. If you want to return only results where the exact phrase is used, just enclose your phrase within quotes. Example:
Oh no, you found a bug!
See our
*In July 2023, OpenAlex switched to a , replaced all OpenAlex Author IDs with new ones. This is a very rare case in which we violate the rule of having stable IDs, which is needed to make the improvements. Old IDs and their connections to works remain available in the historical OpenAlex data.
We automatically index new journals and articles so there is nothing you need to do. We primarily retrieve new records from . So if you are not seeing your journal or article in OpenAlex, it is best to check if it is in Crossref with a query like https://api.crossref.org/works/<doi> (). We do not curate journals or limit which journals will be included in OpenAlex. So any discoverable journals will be added to the data set.
If your example DOI is in Crossref but not in OpenAlex, please send us a so we can look into it further!
Yes. Using coauthors, references, and other features of the data, we can tell that the same Jane Smith wrote both "Frog behavior" and "Frogs: A retrospective," but it's a different Jane Smith who wrote "Oats before boats: The breakfast customs of 17th-Century Dutch bargemen." For more details on this, see the page on .
OpenAlex is not doing this alone! Rather, we're aggregating and standardizing data from a whole bunch of other great projects, like a river fed by many tributaries. Our two most important data sources are and Other key sources include:
Subject-area and institutional repositories from to and everywhere in between
Learn more at our general help center article:
For now, the database snapshot is updated about once per month. We also offer a much faster update cadence—as often as once every few hours—through
OpenAlex data is licensed as so it is free to use and distribute.
It's free! The , the , and the are all available at no charge. As a nonprofit, making this data free and open is part of our mission.
For those who would like a higher level of service and to provide direct financial support for our mission, we offer
Please see the help section on .
Our nonprofit (OurResearch) has a ten-year track record of building sustainable scholarly infrastructure, and a formal commitment to sustainability as part of
We're currently still exploring our options for OpenAlex's sustainability plan. Thanks to a generous grant from , we've got lots of runway, and we don't need to roll anything out in a rush.
Our Unpaywall project (a free index of the world's open-access research literature) has been self-sustaining via a freemium revenue model for nearly five years, and we have recently introduced a similar model in Access to the data will always be free for everyone, but OpenAlex Premium offers several benefits in service above the services we offer for free.
The package is a great way to work with the OpenAlex API using the R programming language, but it is third-party software that we do not maintain ourselves. Please direct any questions you have to them instead.
If you want to count self-citations—or, inversely independent citations where citing and the cited work do not have any authors in common—you can check each citation for whether they share any Author IDs in common in their field. See for more information.
We provide links to the full-text PDFs for open-access works whenever possible. In addition, we have access to raw full-text for many works either through PDF parsing we have done, or using the Internet Archive's general index, which we use to power our . You can learn more about this . We do not currently offer direct access to raw full-text through the API or data snapshot.
Get works with search term "dna" in the title, abstract, or fulltext:
When you , the API looks for matches in titles, abstracts, and . When you , we look in each concept's display_name and description fields. When you , we look at the display_name, alternate_titles, and abbreviated_title fields. When you , we look at the display_name and display_name_alternatives fields. When you , we look at the display_name, display_name_alternatives, and display_name_acronyms fields.
For most text search we remove and use (specifically, the ) to improve results. So words like "the" and "an" are transparently removed, and a search for "possums" will also return records using the word "possum." With the exception of raw affiliation strings, we do not search within words but rather try to match whole words. So a search with "lun" will not match the word "lunar".
Including any of the words AND, OR, or NOT in any of your searches will enable boolean search. Those words must be UPPERCASE. You can use this in all searches, including using the search parameter, and using .
Behind the scenes, the boolean search is using Elasticsearch's on the searchable fields (such as title, abstract, and fulltext for works; see each individual entity page for specifics about that entity). Wildcard and fuzzy searches using *, ? or ~ are not allowed; these characters will be removed from any searches. These searches, even when using quotation marks, will go through the same cleaning as desscribed above, including stemming and removal of stop words.
Search for works that mention "elmo" and "sesame street," but not the words "cookie" or "monster":
Get works with the exact phrase "fierce creatures" in the title or abstract (returns just a few results):
Get works with the words "fierce" and "creatures" in the title or abstract, with works that have the two words close together ranked higher by relevance_score (returns way more results):
You can also use search as a , allowing you to fine-tune the fields you're searching over. To do this, you append .search to the end of the property you are filtering for:
Get authors who have "Einstein" as part of their name:
Get works with "cubist" in the title:
Additionally, the filter default.search is available on all entities; this works the same as the .
You might be tempted to use the search filter to power an autocomplete or typeahead. Instead, we recommend you use the , which is much faster. 👎
👍

%20(1).svg?alt=media)


.svg?alt=media)
.svg?alt=media)
.svg?alt=media)




You can get lists of sources:
Get all sources in OpenAlex https://api.openalex.org/sources
Which returns a response like this:
By default we return 25 results per page. You can change this default and page through sources with the per-page and page parameters:
Get the second page of sources results, with 50 results returned per page https://api.openalex.org/sources?per-page=50&page=2
You also can sort results with the sort parameter:
Sort sources by cited by count, descending https://api.openalex.org/sources?sort=cited_by_count:desc
Continue on to learn how you can filter and search lists of sources.
You can use sample to get a random batch of sources. Read more about sampling and how to add a seed value here.
Get 10 random sources https://api.openalex.org/sources?sample=10
You can use select to limit the fields that are returned in a list of sources. More details are here.
Display only the id, display_name and issn within sources results
https://api.openalex.org/sources?select=id,display_name,issn